朴素贝叶斯
Created|Updated
|Post Views:
朴素贝叶斯
朴素贝叶斯介绍
- 复习常见概率的计算
- 知道贝叶斯公式
- 了解朴素贝叶斯是什么
- 了解拉普拉斯平滑系数的作用
【知道】常见的概率公式
条件概率: 表示事件A在另外一个事件B已经发生条件下的发生概率,P(A|B)
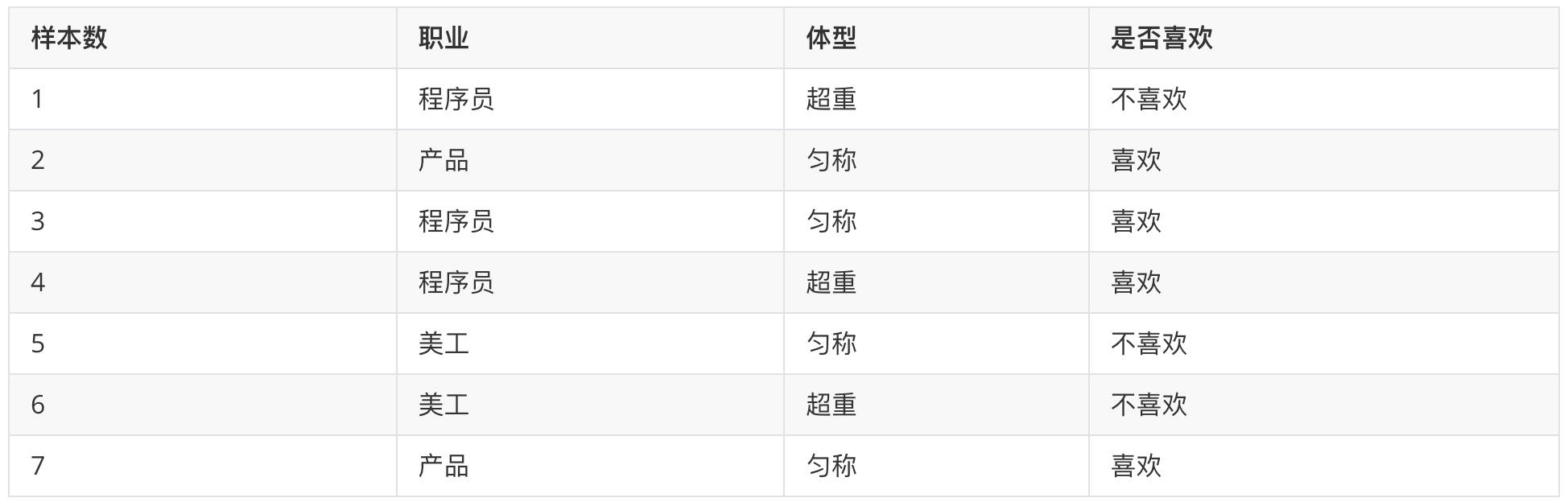
在女神喜欢的条件下,职业是程序员的概率?
- 女神喜欢条件下,有 2、3、4、7 共 4 个样本
- 4 个样本中,有程序员 3、4 共 2 个样本
- 则 P(程序员|喜欢) = 2/4 = 0.5
联合概率: 表示多个条件同时成立的概率,P(AB) = P(A) P(B|A)
特征条件独立性假设:P(AB) = P(A) P(B)
职业是程序员并且体型匀称的概率?
- 数据集中,共有 7 个样本
- 职业是程序员有 1、3、4 共 3 个样本,则其概率为:3/7
- 在职业是程序员,体型是匀称有 3 共 1 个样本,则其概率为:1/3
- 则即是程序员又体型匀称的概率为:3/7 * 1/3 = 1/7
联合概率 + 条件概率:
在女神喜欢的条件下,职业是程序员、体重超重的概率? P(AB|C) = P(A|C) P(B|AC)
- 在女神喜欢的条件下,有 2、3、4、7 共 4 个样本
- 在这 4 个样本中,职业是程序员有 3、4 共 2 个样本,则其概率为:2/4=0.5
- 在在 2 个样本中,体型超重的有 4 共 1 个样本,则其概率为:1/2 = 0.5
- 则 P(程序员, 超重|喜欢) = 0.5 * 0.5 = 0.25
简言之:
条件概率:在去掉部分样本的情况下,计算某些样本的出现的概率,表示为:P(B|A)
联合概率:多个事件同时发生的概率是多少,表示为:P(AB) = P(B)*P(A|B)
【理解】贝叶斯公式
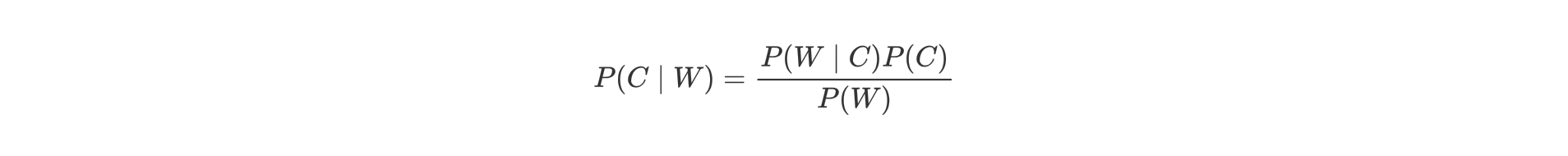
- P(C) 表示 C 出现的概率
- P(W|C) 表示 C 条件 W 出现的概率
- P(W) 表示 W 出现的概率

- P(C|W) = P(喜欢|程序员,超重)
- P(W|C) = P(程序员,超重|喜欢)
- P(C) = P(喜欢)
- P(W) = P(程序员,超重)
- 根据训练样本估计先验概率P(C):P(喜欢) = 4/7
- 根据条件概率P(W|C)调整先验概率:P(程序员,超重|喜欢) = 1/4
- 此时我们的后验概率P(C|W)为:P(程序员,超重|喜欢) * P(喜欢) = 4/7 * 1/4 = 1/7
- 那么该部分数据占所有既为程序员,又超重的人中的比例是多少呢?
- P(程序员,超重) = P(程序员) * P(超重|程序员) = 3/7 * 2/3 = 2/7
- P(喜欢|程序员, 超重) = 1/7 ➗ 2/7 = 0.5
【理解】朴素贝叶斯
我们发现,在前面的贝叶斯概率计算过程中,需要计算 P(程序员,超重|喜欢) 和 P(程序员, 超重) 等联合概率,为了简化联合概率的计算,朴素贝叶斯在贝叶斯基础上增加:特征条件独立假设,即:特征之间是互为独立的。
此时,联合概率的计算即可简化为:
- P(程序员,超重|喜欢) = P(程序员|喜欢) * P(超重|喜欢)
- P(程序员,超重) = P(程序员) * P(超重)
【知道】拉普拉斯平滑系数
由于训练样本的不足,导致概率计算时出现 0 的情况。为了解决这个问题,我们引入了拉普拉斯平滑系数。

- α 是拉普拉斯平滑系数,一般指定为 1
- Ni 是 F1 中符合条件 C 的样本数量
- N 是在条件 C 下所有样本的总数
- m 表示所有独立样本的总数
我们只需要知道为了避免概率值为 0,我们在分子和分母分别加上一个数值,这就是拉普拉斯平滑系数的作用。
【案例】情感分析
学习目标:
1.知道朴素贝叶斯的API
2.能够应用朴素贝叶斯实现商品评论情感分析
【知道】api介绍
- sklearn.naive_bayes.MultinomialNB(alpha = 1.0)
- 朴素贝叶斯分类
- alpha:拉普拉斯平滑系数
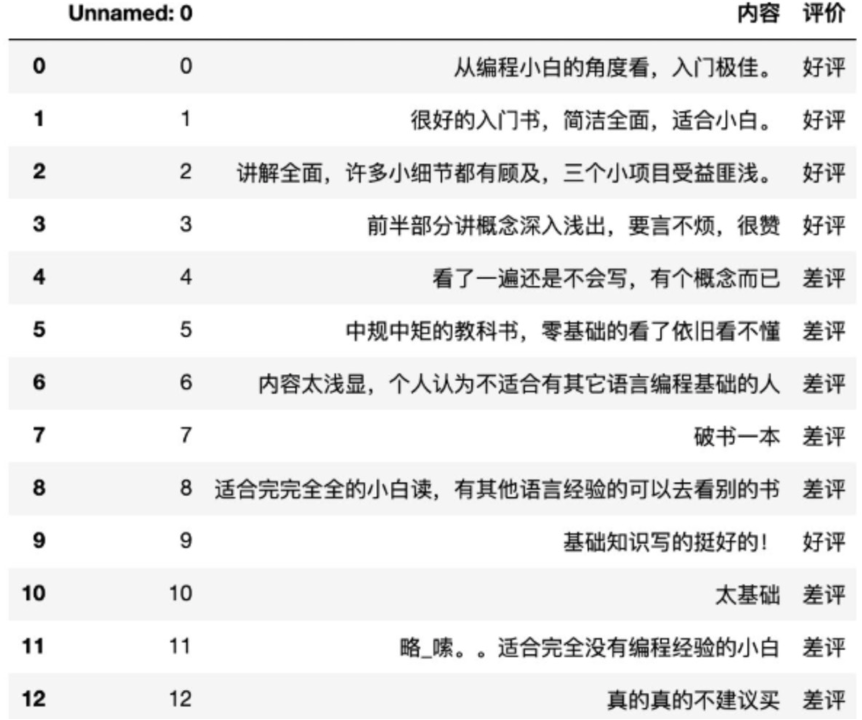
【实践】商品评论情感分析
已知商品评论数据,根据数据进行情感分类(好评、差评
步骤分析
- 1)获取数据
- 2)数据基本处理
- 2.1) 取出内容列,对数据进行分析
- 2.2) 判定评判标准
- 2.3) 选择停用词
- 2.4) 把内容处理,转化成标准格式
- 2.5) 统计词的个数
- 2.6)准备训练集和测试集
- 3)模型训练
- 4)模型评估
代码实现
1 | import pandas as pd |
- 1)获取数据
1 | # 加载数据 |
- 2)数据基本处理
1 | # 2.1) 取出内容列,对数据进行分析 |
- 3)模型训练
1 | # 构建贝叶斯算法分类器 |
- 4)模型评估
1 | mb.score(x_text, y_text) |
Author: 甘虎文
Copyright Notice: All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles
2023-03-15
KNN算法
KNN算法KNN算法简介学习目标: 1.理解K近邻算法的思想 2.知道K值选择对结果影响 3.知道K近邻算法分类流程 4.知道K近邻算法回归流程 【理解】KNN算法思想K-近邻算法(K Nearest Neighbor,简称KNN)。比如:根据你的“邻居”来推断出你的类别 KNN算法思想:如果一个样本在特征空间中的 k 个最相似的样本中的大多数属于某一个类别,则该样本也属于这个类别 思考:如何确定样本的相似性? 样本相似性:样本都是属于一个任务数据集的。样本距离越近则越相似。 利用K近邻算法预测电影类型 【知道】K值的选择 【知道】KNN的应用方式 解决问题:分类问题、回归问题 算法思想:若一个样本在特征空间中的 k 个最相似的样本大多数属于某一个类别,则该样本也属于这个类别 相似性:欧氏距离 分类问题的处理流程: 1.计算未知样本到每一个训练样本的距离 2.将训练样本根据距离大小升序排列 3.取出距离最近的 K 个训练样本 4.进行多数表决,统计 K 个样本中哪个类别的样本个数最多 5.将未知的样本归属到出现次数最多的类别 回归问题的处理流程:...
2023-05-17
决策树
决策树决策树简介学习目标 1.理解决策树算法的基本思想 2.知道构建决策树的步骤 【理解】决策树例子决策树算法是一种监督学习算法,英文是Decision tree。 决策树思想的来源非常朴素,试想每个人的大脑都有类似于if-else这样的逻辑判断,这其中的if表示的是条件,if之后的else就是一种选择或决策。程序设计中的条件分支结构就是if-else结构,最早的决策树就是利用这类结构分割数据的一种分类学习方法。 比如:你母亲要给你介绍男朋友,是这么来对话的: 女儿:多大年纪了? 母亲:26。 女儿:长的帅不帅? 母亲:挺帅的。 女儿:收入高不? 母亲:不算很高,中等情况。 女儿:是公务员不? 母亲:是,在税务局上班呢。 女儿:那好,我去见见。 于是你在脑袋里面就有了下面这张图: 作为女孩的你在决策过程就是典型的分类树决策。相当于通过年龄、长相、收入和是否公务员对将男人分为两个类别:见和不见。 【知道】决策树简介决策树是什么? 决策树是一种树形结构,树中每个内部节点表示一个特征上的判断,每个分支代表一个判断结果的输出,每个叶子节点代表一种分类结果 决策树的建立过程: 1.特征...
2023-03-28
机器学习概述
机器学习概述人工智能三大概念学习目标: 1.知道AL,ML,DL是什么? 2.了解AL、ML、DL之间的关系 3.知道自动学习和规则编程的区别 【知道】人工智能 Artificial Intelligence 人工智能 AI is the field that studies the synthesis and analysis of computational agents that act intelligently AI is to use computers to analog and instead of human brain 释义 - 仿智; 像人一样机器智能的综合与分析;机器模拟人类 释义:是一个系统,像人那样思考 像人那样理性思考 释义:是一个系统,像人那样活动 像人那样合理系统 【知道】机器学习 Machine Learning 释义:机器学习 Field of study that gives computers the ability to learn without being explicitly programme...
2023-08-26
线性回归
线性回归 线性回归介绍学习目标: 1.理解线性回归是什么? 2.知道一元线性回归和多元线性回归的区别 3.知道线性回归的应用场景 【理解】举个栗子假若有了身高和体重数据,来了播仔的身高,你能预测播仔体重吗? 这是一个回归问题,该如何求解呢? 思路:先从已知身高X和体重Y中找规律,再预测 •数学问题:用一条线来拟合身高和体重之间的关系,再对新数据进行预测 方程 Y = kX + b k160 + b = 56.3 – (1) k166 + b = 60.6 –- (2) 。。。。 k: 斜率 b:截距 若:y = 0.9 x + (-93) 0.9*176 +(-93)= ? 【理解】线性回归线性回归(Linear regression)是利用 回归方程(函数) 对 一个或多个自变量(特征值)和因变量(目标值)之间 关系进行建模的一种分析方式。 注意事项: 1 为什么叫线性模型?因为求解的w,都是w的零次幂(常数项)所以叫成线性模型 2 在线性回归中,从数据中获取的规律其实就是学习权重系数w 3 某一...
2023-04-19
聚类
聚类聚类算法简介学习目标: 1.知道什么是聚类 2.了解聚类算法的应用场景 3.知道聚类算法的分类 【知道】聚类算法介绍一种典型的无监督学习算法,主要用于将相似的样本自动归到一个类别中。 在聚类算法中根据样本之间的相似性,将样本划分到不同的类别中,对于不同的相似度计算方法,会得到不同的聚类结果,常用的相似度计算方法有欧式距离法。 【了解】聚类算法在现实中的应用 用户画像,广告推荐,Data Segmentation,搜索引擎的流量推荐,恶意流量识别 基于位置信息的商业推送,新闻聚类,筛选排序 图像分割,降维,识别;离群点检测;信用卡异常消费;发掘相同功能的基因片段 【知道】分类 聚类API的初步使用学习目标: 1.了解Kmeans算法的API 2.动手实践Kmeans算法 【了解】api介绍 sklearn.cluster.KMeans(n_clusters=8) 参数: n_clusters:开始的聚类中心数量 整型,缺省值=8,生成的聚类数,即产生的质心(centroids)数。 方法: estimator.fit(x) estimator....
2023-06-20
逻辑回归
逻辑回归逻辑回归简介学习目标: 1.知道逻辑回归的应用场景 2.复习逻辑回归应用到的数学知识 【了解】应用场景 逻辑回归是解决二分类问题的利器 【熟悉】数学知识【知道】sigmoid函数 【理解】概率 【理解】极大似然估计核心思想: 设模型中含有待估参数w,可以取很多值。已经知道了样本观测值,从w的一切可能值中(选出一个使该观察值出现的概率为最大的值,作为w参数的估计值,这就是极大似然估计。(顾名思义:就是看上去那个是最大可能的意思) 举个例子: 假设有一枚不均匀的硬币,出现正面的概率和反面的概率是不同的。假定出现正面的概率为𝜃, 抛了6次得到如下现象 D = {正面,反面,反面,正面,正面,正面}。每次投掷事件都是相互独立的。 则根据产生的现象D,来估计参数𝜃是多少? 1234P(D|𝜃) = P {正面,反面,反面,正面,正面,正面} = P(正面|𝜃) P(正面|𝜃) P(正面|𝜃) P(正面|𝜃) P(正面|𝜃) P(正面|𝜃)=𝜃 *(1-𝜃)*(1-𝜃)𝜃*𝜃*𝜃 = 𝜃4(1 − 𝜃) 问题转化为...