生成器_正则
Created|Updated
|Post Views:
多线程特点_随机性
1 | import threading |
多线程特点_守护线程
1 | # |
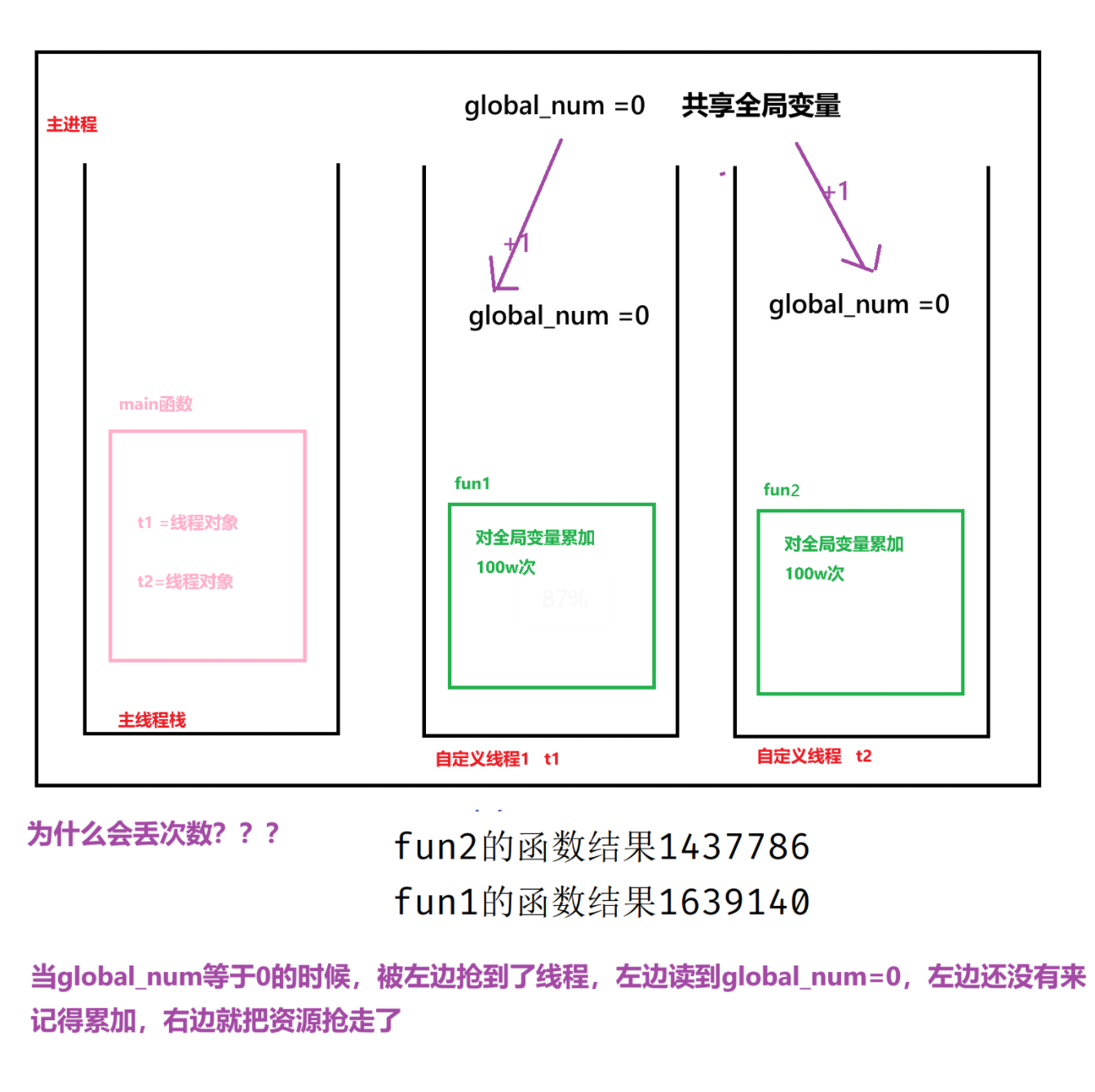
多线程特点_数据共享
1 | # 定义一个列表类型的全局变量,创建两个子线程分别执行 |
多线程特点_互斥锁
图解
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30import threading
global_num = 0
# 创建了一个锁
lk = threading.Lock()
def fun1():
#加锁
lk.acquire()
global global_num
for i in range(10000000):
global_num += 1
print(f"fun1的函数结果{global_num}")
#释放锁
# lk.release()
def fun2():
# 加锁
lk.acquire()
global global_num
for i in range(10000000):
global_num += 1
print(f"fun2的函数结果{global_num}")
lk.release()
# 释放锁
if __name__ == '__main__':
t1 = threading.Thread(target=fun1)
t2 = threading.Thread(target=fun2)
t2.start()
t1.start()
进程和线程对比
2
3
4
1. 线程依赖进程, 进程是CPU分配资源的基本单位, 线程是CPU调度资源的基本单位.
2. 进程更消耗资源, 不能共享全局变量, 相对更稳定.
3. 线程更轻量级, 可以共享全局变量, 相对更灵活.
迭代器入门
1 | """ |
生成器介绍
案例1: 推导式写法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23def my_fun():
for i in range(1, 11):
# my_list =[] #创建
# for i in range(1,11):
# my_list.append(i) #添加
# return my_list #返回
#等价于
# yield 在这里做了三件事
# 1:创建生成器对象
# 2:把值存储在生成器中
# 3:返回生成器
yield i
#1:创建生成器对象
my_g1 = my_fun()
print(type(my_g1))#<class 'generator'>
print(next(my_g1))
print(next(my_g1))
print("*"*24)
for i in my_g1:
print(i)
print("*")案例2: yield关键字
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39"""
案例: 演示生成器之 推导式写法.
生成器介绍:
概述:
所谓的生成器就是基于 数据规则, 用一部分在生成一部分, 而不是一下子生成完所有.
目的:
可以节省大量的内存.
实现方式:
1. 推导式写法.
2. yield关键字
"""
# 需求: 通过yield方式, 获取到生成器之 1 ~ 10之间的整数.
# 回顾: 推导式写法.
my_g = (i for i in range(1, 11))
# yield方式如下.
# 1.定义函数, 存储到生成器中, 并返回.
def my_fun():
# my_list = [] # 创建
# for i in range(1, 11):
# my_list.append(i) # 添加
# return my_list # 返回
# 效果类似于上边的代码.
# yield在这里做了三件事儿: 1.创建生成器对象. 2.把值存储到生成器中. 3.返回生成器.
for i in range(1, 11):
yield i
# 2.测试.
my_g2 = my_fun()
print(type(my_g2)) # <class 'generator'>
print(next(my_g2))
print(next(my_g2))
print('-' * 23)
for i in my_g2:
print(i)案例3: 批量歌词
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32"""
需求:基于传入的文件,创建生成器 ,生产批次歌词
分批加载数据: 歌词 假设 8条为一个批次
"""
import math
# 定义函数 返回生成器
# batch_size 批次大小
def dataset_loader(batch_size):
# 读取文件
with open("./data/jaychou_lyrics.txt", "r", encoding="utf-8") as src_f:
# 一次读取一行数据
lines = src_f.readlines()
# 计算批次总数 ,假设 5批 每个批次8条 5*8 = 40条数据
# 之所以使用math.ceil,是因为考虑到可能最后歌词数不够8条,也算一个批次
# 总批次(total_batch) =celi(len(lines) /batch_size)
total_batch = math.ceil(len(lines) / batch_size)
# 循环 获取到【每个批次】的数据,放入生成器中,并返回
for idx in range(total_batch):
# 如何按照我们的要求来取批次
# 假设total_batch 是5个批次 range(5) 则idx值 0 1 2 3 4
# 第一批歌词,批次索引(idx=0),歌词为:第1条~第8条 索引为0~7
# 第二批格式,批次索引(idx=1),歌词为:第9条~第16条 索引8~15
# 第三批格式,批次索引(idx=2),歌词为:第17条~24条 索引:16~23
# yield lines[0:8] 包左不包右 前面的值 idx * batch_size
# yield lines[8:16] 包左不包右 前面的值 idx *batch_size
yield lines[idx * batch_size:idx * batch_size + batch_size]
d1=dataset_loader(8)
# print(next(d1))
for tmp_batch in d1:
print(tmp_batch)
Property属性介绍
场景1: 装饰器用法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33"""
property属性介绍:
概述/目的/作用:
把函数当做变量来使用
实现方式:
方式一:装饰器
方式二:类属性
实现方式一:
property的装饰器用法
@property 修饰 获取值的函数 get_age
@获取值的函数名.setter 修饰 设置值的函数 set_age
"""
# 没有property属性
class student:
# 私有化属性 age
def __init__(self):
self.__age = 18
# 没有property属性的时候:
# 提供公共的访问接口 (get/set)
@property
def age(self):
return self.__age
@age.setter
def age(self, age):
self.__age = age
if __name__ == '__main__':
s1 = student()
# print(s1.get_age())
# print(s1.get_age)
print(s1.age)
s1.age=20
print(s1.age)场景2: 类属性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40"""
property属性介绍:
概述/目的/作用:
把函数当做变量来使用
实现方式:
方式一:装饰器
方式二:类属性
实现方式一:
property的装饰器用法
@property 修饰 获取值的函数 get_age
@获取值的函数名.setter 修饰 设置值的函数 set_age
"""
# 没有property属性
class student:
# 私有化属性 age
def __init__(self):
self.__age = 18
# 没有property属性的时候:
# 提供公共的访问接口 (get/set)
def get_age(self):
return self.__age
def set_age(self, age):
self.__age = age
age = property(get_age, set_age)
if __name__ == '__main__':
s1 = student()
# print(s1.get_age())
# print(s1.get_age)
print(s1.age)
s1.age = 20
print(s1.age)
正则表达式入门
1 | """ |
正则表达式_校验单个字符
1 | """ |
正则表达式_校验多个字符
1 | import re |
正则表达式_校验开头和结尾
1 | import re |
正则表达式_校验分组
1 | # 1 需求:在列表中["apple", "banana", "orange", "pear"],匹配apple和pearfruit = ["apple", "banana", "orange", "pear"] |
正则表达式_校验邮箱
1 | # 2 需求:匹配出163、126、qq等邮箱 |
正则表达式_提取QQ号
1 | #需求是匹配QQ号 |
正则表达式_校验html
1 | """ |
Author: 甘虎文
Link: http://example.com/2023/08/09/Python%20Advanced/%E7%94%9F%E6%88%90%E5%99%A8_%E6%AD%A3%E5%88%99/
Copyright Notice: All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles
2023-09-12
数据结构与算法
冒泡排序_思路及代码 123456789101112131415161718192021222324252627282930313233343536373839404142"""排序算法稳定性介绍: 概述:排序算法= 把一串数据按照升序或者降序的方式进行排列 方法、思维、方式 分类: 稳定排序算法 排序后,想同元素的相对位置不发生改变 不稳定排序算法 排序后,想同元素的相对位置发生改变 冒泡排序: 原理:相邻元素两两比较,大的往后走,这样第一轮比较厚,最大值在最大索引处 重复该动作,只要排序完毕。 核心: 1:比较的总轮数 列表的长度-1 2:每轮比较的总次数 列表的长度-1-当前轮数的索引 3:谁和谁比较 ? 列表[j]和列表[j+1] 分析流程: 假设元素个数5个 ,具体如下: [5,3,4,7,2] 长度为5 比较的轮数,i...
2023-09-29
数据结构与算法1
数据结构和算法简介 数据结构 就是存储和组织数据的方式, 分为: 线性结构 和 非线性结构 算法 就是解决问题的思路和发放, 它具有独立性, 即: 它不依赖语言, 而是解决问题的思路. Java能做, Python也能做. 特性 有输入, 有输出, 有穷性, 确定性, 可行性. 如何衡量算法的优劣 ==大O标记法,== 即: 将次要条件都省略掉, 最终形成1个表达式. **主要条件:**随着问题规模变化而==变化==的. **次要条件:**随则问题规模变化而==不变==的. 最优和最坏时间复杂度 如非特殊说明, 我们考虑的都是 最坏时间复杂度, 因为它是算法的一种保证. 而最优时间复杂度是算法的 最理想, 最乐观的状况, 没有太大的参考价值. 常见的时间复杂度如下 从最优到最坏分别是: O(1) -> O(logn) -> O(n) -> O(n logn) -> O(n²) -> O(n³) ...
2023-10-31
网络编程_进程_线程
网络编程介绍 概述 就是用来实现网络互联的 不同计算机上 运行的程序间 可以进行数据交互. 三要素 IP地址: 设备(电脑, 手机, Ipad…)在网络中的唯一标识 分类: IPV4, 4字节, 十进制. 例如: 192.168.88.100 IPV6, 8字节, 十六进制, 宣传语: 可以让地球上的每一粒沙子都有自己的IP 两个DOS命令: 查看IP: windows: ipconfig Linux, Mac: ifconfig 测试网络连接: ping ip地址 或者 域名 端口号: 程序在设备(电脑, 手机, Ipad…)上的唯一标识. 范围: 0 ~ 65535, 其中0 ~ 1023已经被系统占用或者用作保留端口, 自定义端口时尽量规避这个范围. 协议: 传输规则, 规范. 常用的协议: TCP(这个用的最多) 和 UDP TCP特点: 1.面向有连接 2.采用字节流传输数据, 理论无大小限制. 3.安全(可靠)...
2023-05-02
闭包_装饰器_深浅拷贝
闭包背景介绍12345678910111213141516171819"""案例目的: 引出闭包相关知识点"""# 定义一个函数用于保存变量10,然后调用函数返回值变量并重复累加数值,观察效果。def func(): num = 10 return numnum = func()print(num + 1) # 11 想要结果是 11print(num + 1) # 11 vs 12print(num + 1) # 11 vs 13# 你会发现无法实现累加!那么如何实现累加呢!! 闭包 闭包入门 12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758# 定义一个用于求和的闭包。# 其中,外部函数有参数num1,内部函数有参数num2,# 然后调用,并用于求解两数之和,观察效果"&qu...
2023-06-03
面向对象基础
面向对象和面向过程 编程思想 就是人们利用计算机来解决问题的思维. 分类 面向过程 它是一种编程思想, 强调的是以 步骤(过程) 为基础完成各种操作. 面向对象 参考思路: 概述, 思想特点, 举例, 总结 它是一种编程思想, 强调的是以 对象 为基础完成各种操作, 它是基于 面向过程的.说到面向对象, 不得不提的就是它的三大思想特点: 1. 更符合人们的思考习惯. 2. 把复杂的事情简单化. 3. 把人们(程序员)从执行者变成指挥者. 举例: 越符合当时的场景越好, 例如: 买电脑, 洗衣服… 总结: 万物接对象. 面向对象特征介绍 三大特征 封装 继承 多态 封装简介 概述 就是隐藏对象的属性和实现细节, 仅对外提供公共的访问方式. 举例 电脑, 手机, 函数, 类 = 属性 + 行为 好处 提高代码的安全性. (私有化) 提高代码的复用性. (函数) 继承 概述 子类继承父类的成员, 例如: 属性, 行为等.大白话: 子承父业. 好处 提高代码的复用性. 多态...
2023-07-07
面向对象进阶
子类重写父类的功能12345678910111213141516171819202122232425262728293031323334353637# 小明掌握了老师傅和黑马的技术后,# 自己潜心钻研出一套自己的独门配方的全新摊煎饼果子技术。"""重写解释: 概念:重写也叫覆盖,即子类出现和父类【重名】的属性或者方法 。称之为重写 调用层次:就近原则 子类用子类的,没有就去找父类的,依次按照继承顺序去找其他父类"""class Master: def __init__(self): self.kongfu = "[古法煎饼果子配方]" def make_cake(self): print(f"运用{self.kongfu}制作煎饼果子")class School: def __init__(self): self.kongfu = "[黑马AI煎饼果子配方]" de...