注意力机制
Created|Updated
|Post Views:
注意力机制
1 注意力机制由来
seq2seq架构介绍(encoder-decoder)
- encoder:编码器, 生成固定上下文张量c
- decoder:解码器, 生成预测序列
- 自回归预测: 只能使用上一时间步的预测结果作为下一时间步的输入
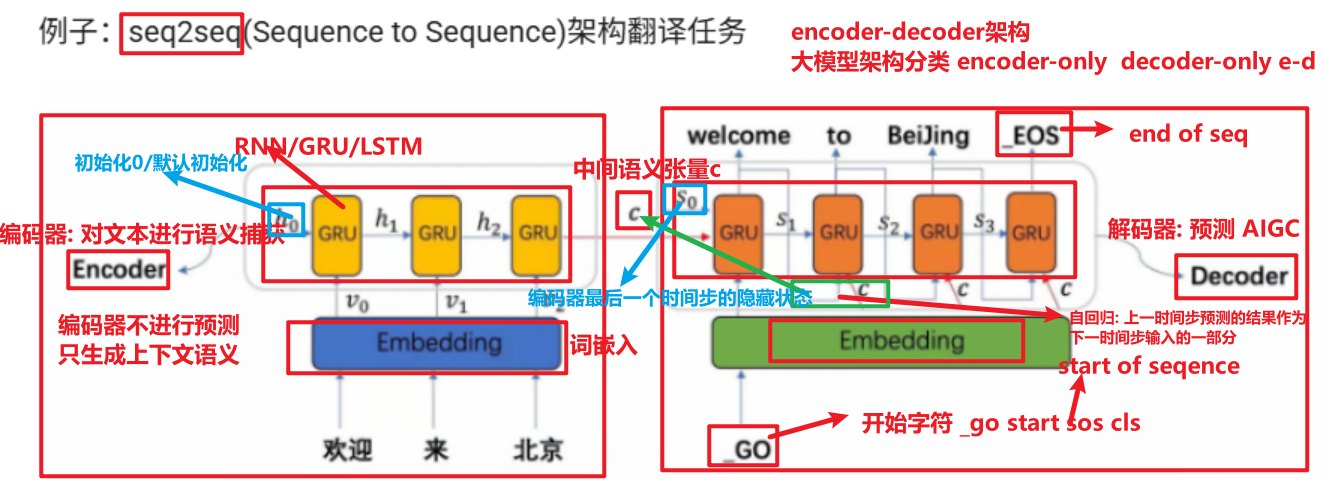
seq2seq架构存在问题
- c不变->信息不变/信息瓶颈
- 使用GRU模型, 处理超长序列时也会产生梯度消失或梯度爆炸
- 基于以上两个问题引用了注意力机制
2 注意力机制介绍
- 概念
- 一种增强神经网络模型性能的技术/工具
- 预测时每个时间步都要计算一个中间语义张量C(动态C) C1,C2,C3…
- C1 = 0.5欢迎 + 0.3来 + 0.2北京
- C2 = 0.3欢迎 + 0.6来 + 0.1北京
- 核心思想
- 通过计算==动态中间语义张量c==来增强模型表达能力
- 作用
- 增强神经网络模型性能
- 增强可解释性 -> 权值
- 缓解信息瓶颈问题 -> 动态C
- 解决长序列问题 -> 使用自注意力机制替换RNN/LSTM/GRU 解决梯度消失或爆炸问题
- 增强神经网络模型性能
3 注意力机制分类
3.1 soft attention(软注意力)
概念: 关注所有的输入词, 给每个词添加0-1之间的概率权重, 所有词的概率权重相加为1
不加attention的seq2seq框架
- 编码器计算==固定长度的中间语义张量c==
- 解码器一步一步解码,每一个时间步使用 固定c和上一时间步预测值融合的结果->X 再和 上一时间步的隐藏状态值 得到当前时间步的预测结果
加attention的seq2seq框架
- 编码器计算每个时间步的隐藏状态值 h1 h2 h3 …
- 计算解码器每个时间步隐藏状态值前权重系数(经过softmax处理) w1h1 w2h2 w3h3…
- h1 h2 h3 拼接结果就是初始的中间语义张量c
- 每个时间步的w1h1进行加权求和计算出动态中间语义张量c
注意力权重(概率)计算 (a11 a12 a13的结果值)
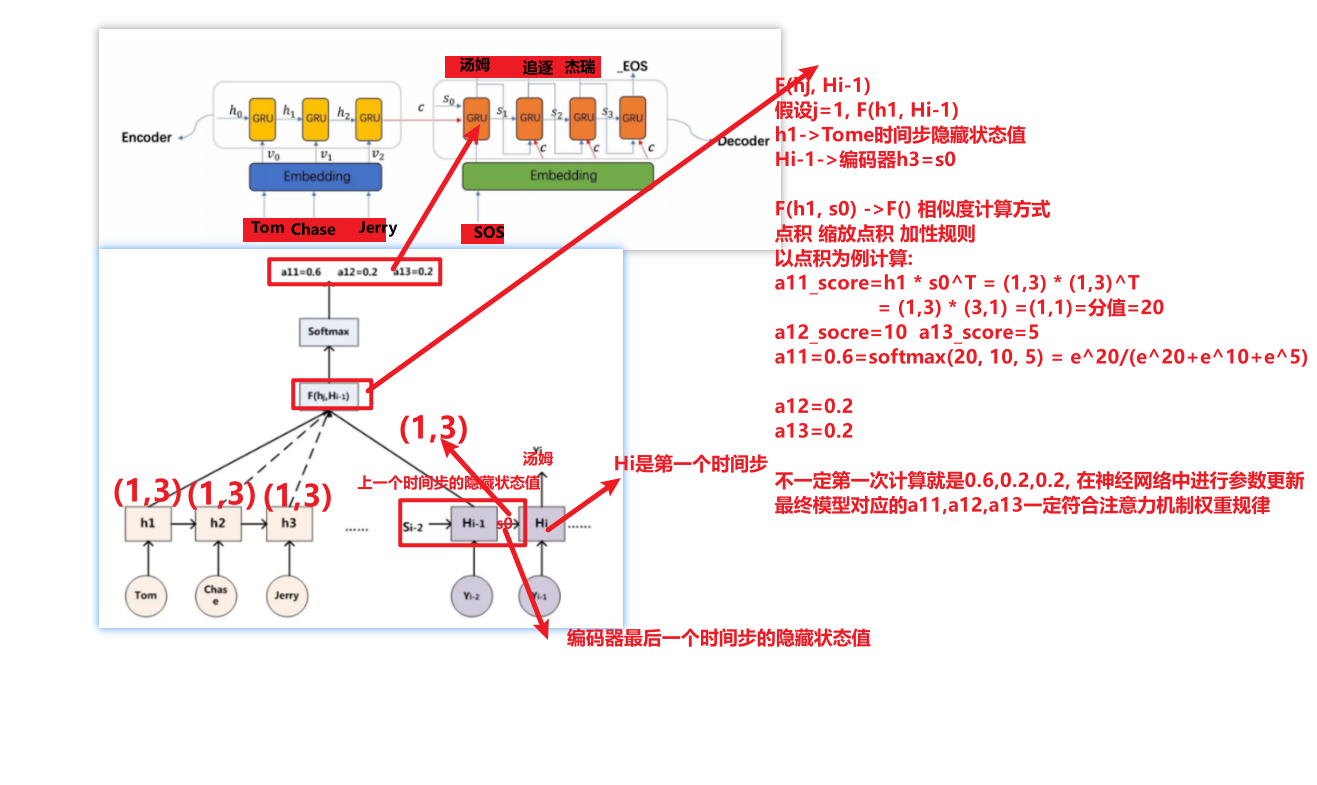
注意力的三步计算流程
- query和key进行相似度计算, 得到 attention score(权重分值)
- 点积
- 缩放点积
- 加性
- attention score经过softmax, 得到 attention prob(权重概率)
- attention prob和value进行加权求和, 得到 动态中间语义张量c
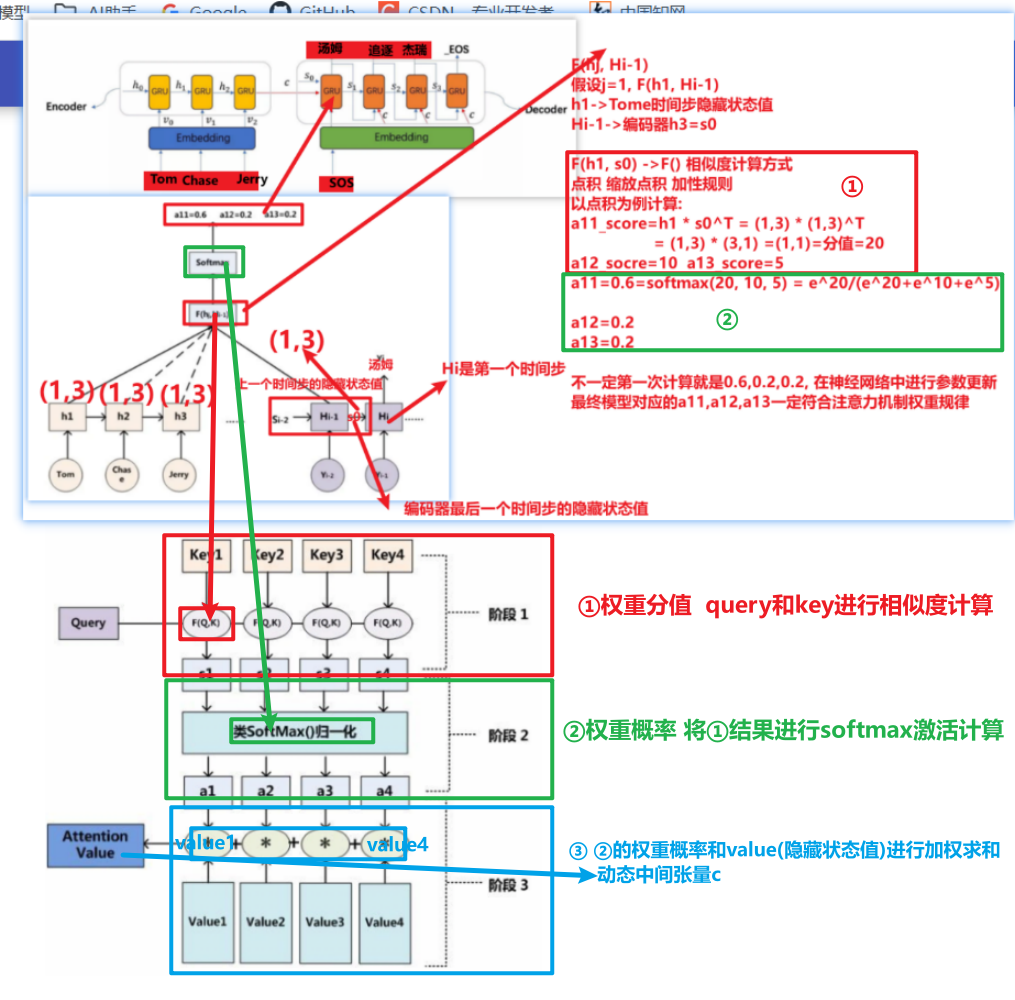
- query和key进行相似度计算, 得到 attention score(权重分值)
query、key、value含义
- query: 解码器时间步的输入x/隐藏状态值
- key: 编码器时间步的词语嵌入向量/隐藏状态值
- value: 编码器时间步的词语嵌入向量/隐藏状态值
- nlp中一般情况下, key=value
- query!=key=value -> 一般注意力机制/软注意力机制
- query=key=value -> 自注意力机制
3.2 hard attention(硬注意力)
概念: 关注部分的输入词, 非0即1, 关注1对应的词
- 选择概率最大k个token,将对应权重设为1,其他的都是0
- 随机采样, 选择k个token
- 在强化学习中使用
3.3 self attention(自注意力)
概念: 舍弃传统的RNN/LSTM/GRU模型, 使用相似度计算的某种方式(缩放点积)算词之间的语义->并行计算, 信息不丢失
- transformer编码器或解码器中 -> query=key=value
- 并行计算两两token之间的相似度
- 编码器端计算==上下文==两两token的相似度
- 解码器端计算==上文==两两token的相似度
4 注意力机制规则
加性注意力
先将q和k根据特征维度进行拼接后进行线性计算 -> softmax -> 和V加权求和(三维矩阵乘法)
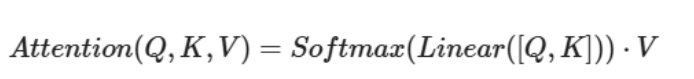
先将q和k根据特征维度进行拼接后进行线性计算[继续进行tanh激活计算,sum求和] -> softmax -> 和V加权求和(三维矩阵乘法)
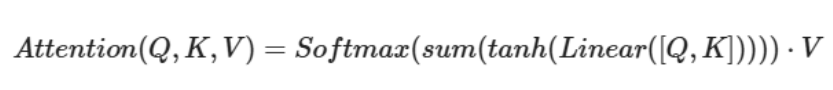
点积注意力
- q和k的转置进行点积 -> softmax -> 和V加权求和(三维矩阵乘法)
缩放点积注意力
q和k的转置进行点积, 点积结果除以sqrt(dk) -> softmax -> 和V加权求和(三维矩阵乘法)
为什么除以sqrt(dk)?
- 防止点击结果值过大, 导致梯度饱和(全为1, 对称性问题)
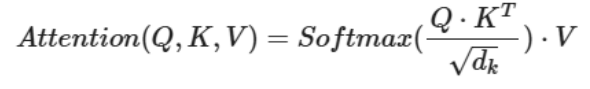
5 深度神经网络的注意力机制
6 seq2seq架构中注意力机制
- 编码器端的注意力机制
- 自注意力机制 query=key=value
- 并行计算两两token之间的语义关系(捕获语义) -> 计算上下文的token
- 自注意力机制 query=key=value
- 解码器端的注意力机制
- 自注意力机制 query=key=value
- 并行计算两两token之间的语义关系(捕获语义) -> 计算上文的token
- 一般注意力机制 query!=key=value
- 让解码器选择性地关注编码器输出的相关信息
- 自注意力机制 query=key=value
Author: 甘虎文
Copyright Notice: All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles
2023-12-20
RNN案例-seq2seq英译法
RNN案例-seq2seq英译法1 RNN案例-seq2seq英译法1.1 seq2seq模型介绍 模型结构 编码器 encoder 解码器 decoder 编码器和解码器中可以使用RNN模型或者是transformer模型 工作流程 编码器生成上下文语义张量 -> 什么是nlp? 将问题转换成语义张量 解码器根据编码器的语义张量和上一时间步的预测值以及上一时间步的隐藏状态值进行当前时间步的预测 自回归模式 局限性 信息瓶颈问题 长序列问题 1.2 数据集介绍 每行样本由英文句子和法文句子对组成, 中间用\t分隔开 英文句子是编码器的输入序列, 法文句子是解码器的输出序列(预测序列)对应的真实序列 1.3 案例实现步骤1.3.1 文本清洗工具函数 utils.py 123456789101112131415161718192021222324252627282930313233343536373839404142434445# 用于正则表达式import re# 用于构建网络结构和函数的torch工具包import torchimport torch...
2024-02-25
fasttext工具
fasttext工具1 fasttext工具1.1 介绍 概念 是一种文本分类和词向量训练的高效工具 作用 文本分类 (分类模型) 训练高质量词向量 (词嵌入模型) 特点 高效, 快 适用于大规模数据集 1.2 架构(了解) fasttext模型组成 输入层 词向量 -> 根据词和词子词信息 词:apple 子词:app ppl ple skipgram模型 CBOW模型 隐藏层 加权求和 -> 文本向量表示 输出层 文本分类 线性层 softmax层 层次softmax 由霍夫曼二叉树组成 二叉树转换成是否问题 二分类问题 树路径越短, 词概率越大; 树路径越长, 词概率越小 层次softmax最多只需要计算 $$log_2词数$$ 次数, 普通的softmax计算 词数 的次数 负采样 将输出层的神经元分为正负两类, 正例神经元1个, 其余都是负例神经元 在负例神经元中随机选择2-5个/5-20个进行反向传播 其他Bert/GPT模型对所有的神经元进行反向传播 1.3 文本分类 概念: 将输入文本分...
2024-01-05
seq2seq
seq2seq1 RNN案例-seq2seq英译法1.1 seq2seq模型介绍 模型结构 编码器 encoder 解码器 decoder 编码器和解码器中可以使用RNN模型或者是transformer模型 工作流程 编码器生成上下文语义张量 -> 什么是nlp? 将问题转换成语义张量 解码器根据编码器的语义张量和上一时间步的预测值以及上一时间步的隐藏状态值进行当前时间步的预测 自回归模式 局限性 信息瓶颈问题 长序列问题 1.2 数据集介绍 每行样本由英文句子和法文句子对组成, 中间用\t分隔开 英文句子是编码器的输入序列, 法文句子是解码器的输出序列(预测序列)对应的真实序列 1.3 案例实现步骤1.3.1 文本清洗工具函数 utils.py 123456789101112131415161718192021222324252627282930313233343536373839404142434445# 用于正则表达式import re# 用于构建网络结构和函数的torch工具包import torchimport torch.nn as nn...
2024-01-22
transformer
transformer1 transformer介绍 概念 transformer是基于自注意力机制的seq2seq模型/架构/框架 核心思想 基于注意力机制 自注意力 一般注意力 作用 捕获超长距离语义关系 并行计算 灵活性: 处理不同的数据, 文本/语音/图像/视频 扩展性: 层数和多头数量可调, transformer默认是6层, 8个头 2 transformer架构 输入部分 词嵌入层 位置编码层 输出部分 线性层 softmax层 编码器部分 多头自注意力子层 前馈全连接子层 残差连接层 规范化层(层归一化) 解码器部分 掩码多头自注意力子层 编码器-解码器堵头一般注意力子层 前馈全连接子层 残差连接层 规范化层(层归一化) 3 输入3.1 文本嵌入层 概念 将token转换成词向量过程 nn.Embedding() 代码实现 1234567891011121314151617181920212223242526272829303132333435363738# 输入部分是由...
2024-03-13
transformers库使用
transformers库使用1 transformers库使用1.1 transformers库是什么 收集预训练模型的开源库 各种开源大模型以及数据集 访问https://huggingface.co需要科学上网 1.2 transformers库使用12345678910# 创建虚拟环境conda create --name 虚拟环境名称 python=3.10# 切换虚拟环境conda activate 虚拟环境名称# 安装transformers库pip install transformers -i https://mirrors.aliyun.com/pypi/simple/# 安装datasets库pip install datasets -i https://mirrors.aliyun.com/pypi/simple/# 安装torch cpu/gpu 当前是cpu版本pip install torch -i https://mirrors.aliyun.com/pypi/simple/ 管道方式 文本分类任务 12345678910111213...
2023-12-03
注意力机制应用
注意力机制应用1 注意力机制应用 思路: 解码器端的一般注意力机制(加性注意力) 实现步骤: q和k按特征维度轴进行拼接torch.concat(), 经过线性层计算nn.linear(), 再经过softmax激活层计算torch.softmax(, dim=-1), 得到权重概率矩阵 将上一步的权重概率矩阵和V进行矩阵乘法torch.bmm(), 得到动态张量c q和动态张量c进行融合, 按特征维度轴进行拼接torch.concat(), 经过线性层计算nn.linear(), 得到融合的结果->解码器当前时间步的输入X output, hn=nn.gru(X, h0) 代码实现 1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768697071727374757677import torchimport torch.nn as nn# 创建神经...