新零售行业评价决策系统
新零售行业评价决策系统
一、项目介绍【理解】
1、项目背景
- 随着科技的迅速发展和智能设备的普及,AI技术在新零售行业中得到了广泛应用。其中 智能推荐系统 是AI技在新零售中最为常见且有效的应用之一。通过分析用户的购买历史、浏览行为以及喜好偏好,推荐系统可以根据个人特征给用户进行个性化商品推荐。这种个性化推荐不仅可以提高用户购买意愿,减少信息过载,还可以带来更高的用户满意度和销量。
- 在智能推荐系统中,文本分类的应用属于重要的应用环节。比如:某电商网站都允许用户为商品填写评论,这些文本评论能够体现出用户的偏好以及商品特征信息,是一种语义信息丰富的隐式特征。 相比于单纯的利用显式评分特征,文本信息一方面可以弥补评分稀疏性的问题,另一方面在推荐系统的可解释方面也能够做的更好。
- 因此,本次项目我们将 以”电商平台用户评论”为背景,基于深度学习方法实现评论文本的准确分类 ,这样做的目的是通过用户对不同商品或服务的评价,平台能够快速回应用户需求,改进产品和服务。同时,自动分类也为个性化推荐奠定基础,帮助用户更轻松地找到符合其偏好的商品。
2、评论文本分类实现方法
2.1 传统的深度学习方法
- 目前实现文本分类的方法很多,如经典的应用于文本的卷积神经网络(Text-CNN)、循环神经网络(Text-RNN)、基于BERT等预训练模型的fine-tuning等,但是这些方法多为建立在具有大量的标注数据下的有监督学习。在很多实际场景中,由于领域特殊性和标注成本高,导致标注训练数据缺乏,模型无法有效地学习参数,从而易出现过拟合现象。因此,如何 通过小样本数据训练得到一个性能较好的分类模型 是目前的研究热点。
2.2 模型微调方法
- 基于前面章节的介绍,我们可以借助Prompt-Tuning的技术,来实现模型部分参数的微调(当然如果模型参数较小比如BERT,也可以全量参数微调),相比传统技术方法,Prompt-Tuning方法可以实现在较少样本的训练上,就可以达到较好的结果。
- 在本次项目中,我们将分别基于 BERT+PET(硬模版)以及BERT+P-Tuning(软模版) 两种方式实现用户评论文本的分类。重点是理解prompt的构造方法,以及promt-tuning方法的实现原理。
二、BERT+PET方式介绍【理解】
1、==PET回顾==
- PET(PatternExploiting Training)的核心思想是:==根据先验知识人工定义模版,将目标分类任务转换为与MLM一致的完形填空,然后再去微调MLM任务参数。==

图中示例1: 情感分类任务(好评还是差评),原始文本:这家店真不错,值得推荐。PET模板: [MASK]满意。Label:不/很。标签词映射(Label Word Verbalizer):例如如果
[MASK]预测的词是“不”,则认为是差评类,如果是“很”,则认为是好评类。图中示例2:新闻分类任务(多分类),原始文本:中国女排再夺冠!PET模版:下面是[MASK] [MASK]新闻,Label:体育/财经/时政/军事
- PET 方法的核心步骤
PET方法整体过程可以概括为:首先,将下游任务通过人工模板(pattern)转化为语言模型的填空任务,并通过verbalizer把预测的词映射到任务标签,从而用少量标注样本训练多个“子模型”;接着,这些子模型在大量未标注数据上生成伪标签,形成软标注数据;最后,通过知识蒸馏,训练一个单一的学生模型来学习多个子模型的预测分布,从而兼顾鲁棒性和泛化能力。在这里,我们只需要完成分类任务,所以只需要实现第一步即可。
具体步骤如下:
1)定义任务模式 (Task Patterns):
- 首先,你需要将下游任务的输入和输出,转换为一种 包含空白([MASK] 或其他特殊标记)的自然语言句子模板 。这些模板被称为“模式”。
- 示例 (情感分类):
- 原始输入:
这部电影太棒了!标签:积极 - POFT 模式:
这部电影太棒了!这是一部____的电影。(其中____是待填充的空白)
- 原始输入:
- 示例 (问题回答 - 抽取式):
- 原始输入:
上下文:北京是中国的首都。问题:中国的首都是哪里?答案:北京 - POFT 模式:
根据上下文:北京是中国的首都。中国的首都是哪里?答案是____。
- 原始输入:
2) 定义标签映射 (Verbalizer):
- 对于任务的每个标签(或答案),你需要将其映射到 PLM(预训练语言模型) 词汇表中的一个或多个 具体词汇 。
- 示例 (情感分类):
积极→好,棒,优秀消极→差,烂,糟糕
- 示例 (问题回答): 答案本身就是模型需要生成的词语。
3) 构造训练样本:
- 将你的 所有有标签的训练数据 ,根据定义的模式和标签映射进行转换。
- 对于每个样本,输入变成模式化的句子,而模型的训练目标是在空白处生成正确的 Verbalizer 词汇(或答案词汇)。
4) 全量微调 PLM:
- 在这些 模式化 、 转换后的训练数据 上,对 整个预训练语言模型进行全量微调 。
- 微调的目标函数通常是 交叉熵损失 ,旨在最大化模型在空白处预测正确 Verbalizer 词汇的概率。这实际上是回归到 PLM 预训练时的 语言模型目标 (如掩码语言模型或文本生成)。
- 区别于 Prompt Engineering: PFT 在这里 更新模型的所有参数 ,而不仅仅是 Prompt 向量。
- 区别于传统 Fine-tuning: 传统 Fine-tuning 可能是在 PLM 上添加一个专门的分类头或抽取层进行微调。而 POFT 则是让 PLM 通过 预测词汇 来完成任务,更接近其预训练的方式。
5) 推理阶段:
- 对于新的输入,同样通过模式进行转换。
- 将转换后的输入送入微调后的 PLM。
- 模型会在空白处生成最可能的词汇。通过 Verbalizer,将这些预测的词汇反向映射回任务的原始标签或答案。
- 例如,如果模型预测
好的概率最高,就将其映射为积极。
- 例如,如果模型预测
2、 环境准备
本项目基于 torch+ transformers 实现,运行前请安装相关依赖包:
- python==3.10
- transformers==4.40.2
- torch==2.5.1+cu121
- datasets==3.6.0
- scikit-learn==1.7.0
3、项目架构
项目架构流程图:

项目整体代码介绍:

三、BERT+PET方式数据预处理【理解】
- 本项目中对数据部分的预处理步骤如下:
- 查看项目数据集
- 编写Config类项目文件配置代码
- 编写数据处理相关代码
1、查看项目数据集
数据存放位置:llm_tuning/prompt_tasks/PET/data
data文件夹里面包含4个txt文档,分别为:train.txt、dev.txt、prompt.txt、verbalizer.txt
1.1 train.txt
- train.txt为训练数据集,其部分数据展示如下:
1 | 水果 脆脆的,甜味可以,可能时间有点长了,水分不是很足。 |
train.txt一共包含63条样本数据,每一行用
\t分开,前半部分为标签(label),后半部分为原始输入 (用户评论)。如果想使用自定义数据训练,只需要仿照上述示例数据构建数据集即可。
1.2 dev.txt
- dev.txt为验证数据集,其部分数据展示如下:
1 | 书籍 "一点都不好笑,很失望,内容也不是很实用" |
dev.txt一共包含590条样本数据,每一行用
\t分开,前半部分为标签(label),后半部分为原始输入 (用户评论)。如果想使用自定义数据训练,只需要仿照上述示例数据构建数据集即可。
1.3 prompt.txt
- prompt.txt为人工设定提示模版,其数据展示如下:
1 | 这是一条{MASK}评论:{textA} |
其中,用大括号括起来的部分为「自定义参数」,可以自定义设置大括号内的值。
示例中 {MASK} 代表 [MASK] token 的位置,{textA} 代表评论数据的位置。
你可以改为自己想要的模板,例如想新增一个 {textB} 参数:
1.4 verbalizer.txt
verbalizer.txt 主要用于定义「真实标签」到「标签预测词」之间的映射。在有些情况下,将「真实标签」作为 [MASK] 去预测可能不具备很好的语义通顺性,因此,我们会对「真实标签」做一定的映射。
例如:
1 | "中国爆冷2-1战胜韩国"是一则[MASK][MASK]新闻。 体育 |
这句话中的标签为「体育」,但如果我们将标签设置为「足球」会更容易预测。
因此,我们可以对「体育」这个 label 构建许多个子标签,在推理时,只要预测到子标签最终推理出真实标签即可,如下:
1 | 体育 -> 足球,篮球,网球,棒球,乒乓,体育 |
- 项目中标签词映射数据展示如下:
1 | 电脑 电脑 |
verbalizer.txt 一共包含10个类别,上述数据中,我们使用了1对1的verbalizer, 如果想定义一对多的映射,只需要在后面用”,”分割即可, eg:
若想使用自定义数据训练,只需要仿照示例数据构建数据集
2、编写Config类项目文件配置代码
代码路径:llm_tuning/prompt_tasks/PET/pet_config.py
config文件目的:配置项目常用变量,一般这些变量属于不经常改变的,比如:训练文件路径、模型训练次数、模型超参数等等
具体代码实现:
1 | import torch |
3、编写数据处理相关代码
代码路径:llm_tuning/prompt_tasks/PET/data_handle/
data_handle文件夹中一共包含三个py脚本:template.py、data_preprocess.py、data_loader.py
3.1 ==template.py==
- 目的:构建固定模版类,text2id的转换
- 思路:
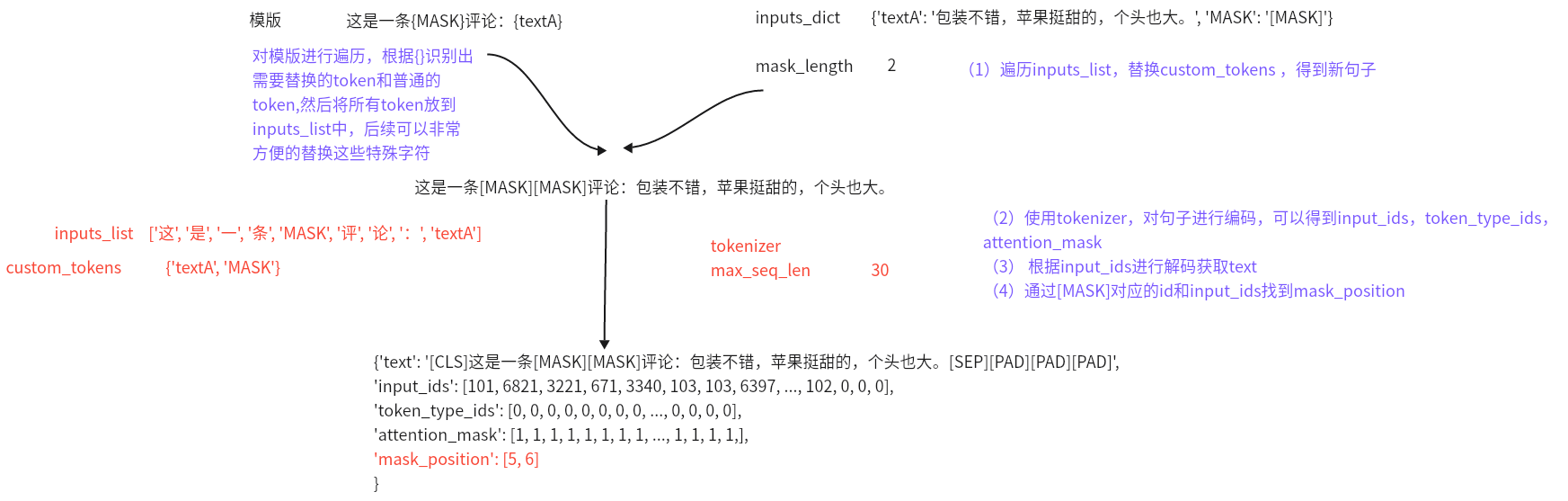
- 定义HardTemplate类代码如下:
1 | from transformers import AutoTokenizer |
3.2 ==data_preprocess.py==
- 目的: 将样本数据转换为模型接受的输入数据。具体来说,就是将每行数据进行处理,获取数据的标签和评论信息,然后进行处理获取输入和标签。
- 定义数据转换方法convert_example(),代码如下:
1 | import numpy as np |
3.3 data_loader.py
- 目的:定义数据加载器
- 定义获取数据加载器的方法get_data(),代码如下:
1 | from functools import partial |
四、PET方式模型搭建与训练【实现】
- 本项目中完成BERT+PET模型搭建、训练及应用的步骤如下(注意:因为本项目中使用的是BERT预训练模型,所以直接加载即可,无需重复搭建模型架构):
- 1.实现模型工具类函数
- 2.实现模型训练函数,验证函数
- 3.实现模型预测函数
1、实现模型工具类函数
- 目的:模型在训练、验证、预测时需要的函数
- 代码路径:llm_tuning/prompt_tasks/PET/utils
- utils文件夹共包含3个py脚本:verbalizer.py、metirc_utils.py以及common_utils.py
1.1 verbalizer.py
- 目的:定义一个Verbalizer类,用于将一个主标签映射到子标签或者将子标签映射到主标签。
- 思路:

- 具体实现代码:
1 | # Union 是 typing 模块中定义的一个类,用于表示多个类型中的任意一种类型 |
1.2 common_utils.py
- 目的:定义损失函数、将mask_position位置的token logits转换为token的id。
==损失计算思路==:
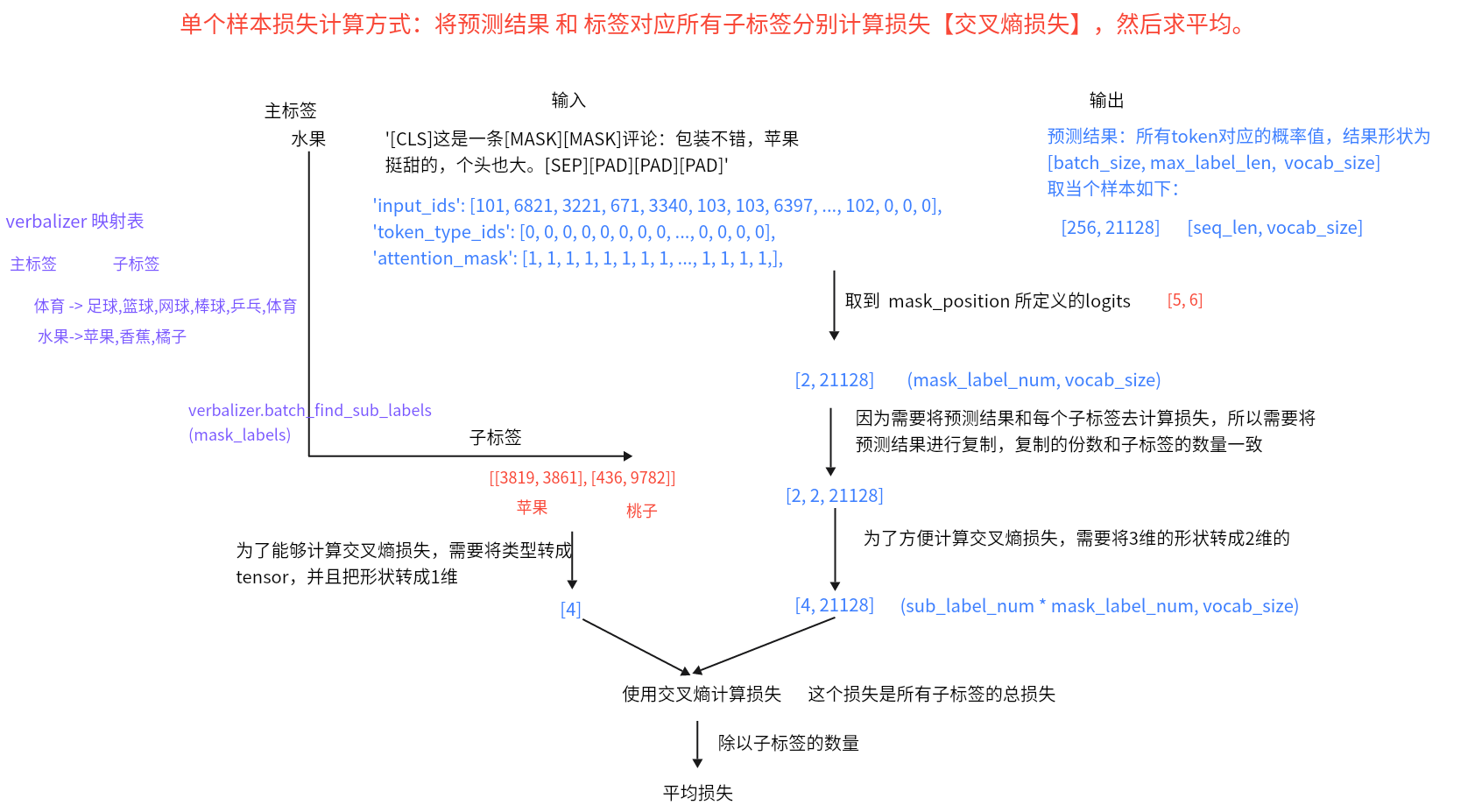
将logits获取id的思路:
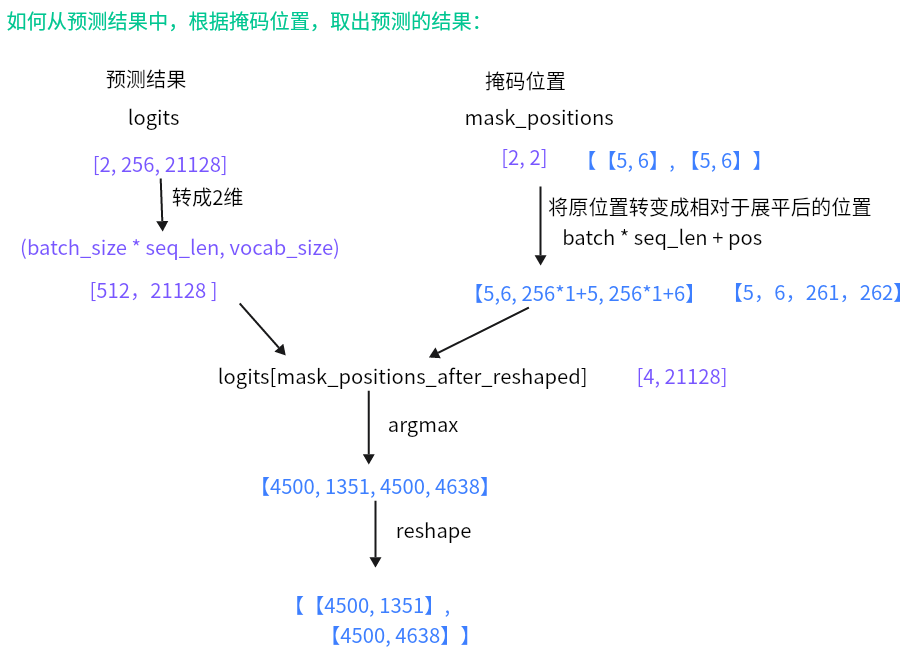
- 脚本里面包含两个函数:mlm_loss()以及convert_logits_to_ids()
- 代码如下:
1 | import torch |
1.3 metirc_utils.py
- 目的:定义(多)分类问题下的指标评估(acc, precision, recall, f1)。
- 定义ClassEvaluator类,代码如下:
1 | from typing import List |
2、实现模型训练函数,验证函数
目的:实现模型的训练和验证
脚本里面包含两个函数:model2train()和evaluate_model()
代码路径:llm_tuning/prompt_tasks/PET/train.py
代码如下:
1 | import os |
- 输出结果:
1 | ..... |
- 结论: BERT+PET模型在训练集上的表现是精确率=78%
- 注意:本项目中只用了60条样本,在接近600条样本上精确率就已经达到了78%,如果想让指标更高,可以扩增样本。
3、实现模型预测函数
目的:加载训练好的模型并测试效果
代码路径:llm_tuning/prompt_tasks/PET/inference.py
代码如下:
1 | import os |
- 结果展示
1 | { |
五、BERT+P-Tuning方式介绍【理解】
1、P-Tuning回顾
- P-Tuning(Pattern-Tuning)是一种连续空间可学习模板,PET的目的解决PET的缺点,使用可学习的向量作为伪模板,不再手动构建模板。

以新闻分类任务为例:原始文本:中国女排再夺冠!P-Tuning可学习模板:[u1] [u2] …[MASK]…[un], Label:体育/财经/时政/军事
- P-tuning 的核心思想是:用一个小的可训练模块把一组“连续提示向量”生成并插入到原始输入 embedding 中,令冻结的预训练模型在下游任务上产生正确输出,训练时仅更新 prompt encoder(或提示向量),从而实现低成本高效的调优。
2、环境准备
本项目基于 pytorch + transformers 实现,运行前请安装相关依赖包:
- python==3.10
- transformers==4.40.2
- torch==2.5.1+cu121
- datasets==3.6.0
- scikit-learn==1.7.0
3、项目架构
- 项目架构流程图:

- 项目整体代码介绍:
六、BERT+P-Tuning方式数据预处理【理解】
本项目中对数据部分的预处理步骤如下:
- 1.查看项目数据集
- 2.编写Config类项目文件配置代码
- 3.编写数据处理相关代码
1、查看项目数据集
数据存放位置:llm_tuning/prompt_tasks/P-Tuning/data
data文件夹里面包含3个txt文档,分别为:train.txt、dev.txt、verbalizer.txt
1.1 train.txt
- train.txt为训练数据集,其部分数据展示如下:
1 | 水果 脆脆的,甜味可以,可能时间有点长了,水分不是很足。 |
train.txt一共包含63条样本数据,每一行用
\t分开,前半部分为标签(label),后半部分为原始输入 (用户评论)。如果想使用自定义数据训练,只需要仿照上述示例数据构建数据集即可。
1.2 dev.txt
- dev.txt为验证数据集,其部分数据展示如下:
1 | 书籍 "一点都不好笑,很失望,内容也不是很实用" |
dev.txt一共包含417条样本数据,每一行用
\t分开,前半部分为标签(label),后半部分为原始输入 (用户评论)。如果想使用自定义数据训练,只需要仿照上述示例数据构建数据集即可。
1.3 verbalizer.txt
verbalizer.txt 主要用于定义「真实标签」到「标签预测词」之间的映射。在有些情况下,将「真实标签」作为 [MASK] 去预测可能不具备很好的语义通顺性,因此,我们会对「真实标签」做一定的映射。
例如:
1 | "中国爆冷2-1战胜韩国"是一则[MASK][MASK]新闻。 体育 |
这句话中的标签为「体育」,但如果我们将标签设置为「足球」会更容易预测。
因此,我们可以对「体育」这个 label 构建许多个子标签,在推理时,只要预测到子标签最终推理出真实标签即可,如下:
1 | 体育 -> 足球,篮球,网球,棒球,乒乓,体育 |
- 项目中标签词映射数据展示如下:
1 | 电脑 电脑 |
verbalizer.txt 一共包含10个类别,上述数据中,我们使用了1对1的verbalizer, 如果想定义一对多的映射,只需要在后面用”,”分割即可, eg:
若想使用自定义数据训练,只需要仿照示例数据构建数据集
2、编写Config类项目文件配置代码
代码路径:llm_tuning/prompt_tasks/P-Tuning/ptune_config.py
config文件目的:配置项目常用变量,一般这些变量属于不经常改变的,比如:训练文件路径、模型训练次数、模型超参数等等
具体代码实现:
1 | import torch |
3、编写数据处理相关代码
代码路径:llm_tuning/prompt_tasks/P-Tuning/data_handle/
data_handle文件夹中一共包含两个py脚本:data_preprocess.py、data_loader.py
3.1 data_preprocess.py
- 目的: 将模板与原始输入文本进行拼接,构造模型接受的输入数据
- 代码如下:
1 | import torch |
打印结果展示:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
[ 1, 2, 3, ..., 3300, 5741, 102],
[ 1, 2, 3, ..., 6574, 7030, 0],
...,
[ 1, 2, 3, ..., 8024, 2571, 0],
[ 1, 2, 3, ..., 3221, 3175, 102],
[ 1, 2, 3, ..., 5277, 3688, 102]]),
'attention_mask': array([[1, 1, 1, ..., 1, 1, 1],
[1, 1, 1, ..., 1, 1, 1],
[1, 1, 1, ..., 1, 1, 0],
...,
[1, 1, 1, ..., 1, 1, 0],
[1, 1, 1, ..., 1, 1, 1],
[1, 1, 1, ..., 1, 1, 1]]),
'mask_positions': array([[7, 8],
[7, 8],
[7, 8],
...,
[7, 8],
[7, 8],
[7, 8]]),
'mask_labels': array([[4510, 5554],
[3717, 3362],
[2398, 3352],
...,
[3819, 3861],
[6983, 2421],
[3819, 3861]]),
'token_type_ids': array([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]])}
3.2 data_loader.py
目的:定义数据加载器
代码如下:
1 | from functools import partial |
打印结果展示:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
[1, 2, 3, ..., 0, 0, 0],
[1, 2, 3, ..., 0, 0, 0],
...,
[1, 2, 3, ..., 0, 0, 0],
[1, 2, 3, ..., 0, 0, 0],
[1, 2, 3, ..., 0, 0, 0]]),
'attention_mask': tensor([[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
...,
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0]]),
'mask_positions': tensor([[7, 8],
[7, 8],
[7, 8],
[7, 8],
[7, 8],
[7, 8],
[7, 8],
[7, 8]]),
'mask_labels': tensor([[6132, 3302],
[3717, 3362],
[6132, 3302],
[6983, 2421],
[6983, 2421],
[6132, 3302],
[3717, 3362],
[2398, 3352]]),
'token_type_ids': tensor([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]])}
torch.int64
七、BERT+P-Tuning方式模型搭建与训练【实现】
本项目中完成BERT+P-Tuning模型搭建、训练及应用的步骤如下(注意:因为本项目中使用的是BERT预训练模型,所以直接加载即可,无需重复搭建模型架构):
- 1.实现模型工具类函数
- 2.实现模型训练函数,验证函数
- 3.实现模型预测函数
1、实现模型工具类函数
- 目的:模型在训练、验证、预测时需要的函数
- 代码路径:llm_tuning/prompt_tasks/P_Tuning/utils
- utils文件夹共包含3个py脚本:verbalizer.py、metirc_utils.py以及common_utils.py
1.1 verbalizer.py
- 目的:定义一个Verbalizer类,用于将一个Label对应到其子Label的映射。
- 具体代码如下:
1 | # Union 是 typing 模块中定义的一个类,用于表示多个类型中的任意一种类型 |
print结果显示:
2
3
4
5
6
7
8
ret-->{'sub_labels': ['电脑'], 'token_ids': [[4510, 5554]]}
********************************************************************************
result-->[{'sub_labels': ['电脑'], 'token_ids': [[4510, 5554]]}, {'sub_labels': ['衣服'], 'token_ids': [[6132, 3302]]}]
********************************************************************************
ret-->{'label': '电器', 'token_ids': [4510, 1690]}
********************************************************************************
ret-->[{'label': '衣服', 'token_ids': [6132, 3302]}, {'label': '蒙牛', 'token_ids': [5885, 4281]}]
1.2 common_utils.py
- 目的:定义损失函数、将mask_position位置的token logits转换为token的id。
- 脚本里面包含两个函数:mlm_loss()以及convert_logits_to_ids()
- 代码如下:
1 | import torch |
1.3 metirc_utils.py
- 目的:定义(多)分类问题下的指标评估(acc, precision, recall, f1)。
- 代码如下:
1 | from typing import List |
print代码结果:
2
3
4
5
6
7
8
9
'precision': 0.7,
'recall': 0.6,
'f1': 0.6,
'class_metrics':
{'体育': {'precision': np.float64(0.5), 'recall': np.float64(0.5), 'f1': np.float64(0.5)},
'计算机': {'precision': np.float64(1.0), 'recall': np.float64(0.5), 'f1': np.float64(0.67)},
'财经': {'precision': np.float64(0.5), 'recall': np.float64(1.0), 'f1': np.float64(0.67)}
}}
2、实现模型训练函数,验证函数
目的:实现模型的训练和验证,脚本里面包含两个函数:model2train()和evaluate_model()
代码路径:llm_tuning/prompt_tasks/P_Tuning/train.py
代码如下:
1 | import os |
- 输出结果:
1 | ... |
- 结论: BERT+P-Tuning模型在训练集上的表现是Precion: 76%
- 注意:本项目中只用了60条样本,在接近400条样本上精确率就已经达到了76%,如果想让指标更高,可以扩增样本。
提升模型性能:
增加训练数据集(100条左右的数据):
1 | 手机 外观时尚新潮,适合年轻人展现个性。 |
修改验证集脏数据
1 | # 原始标签和评论文本内容不符 |
模型表现:
Evaluation precision: 0.79000, recall: 0.70000, F1: 0.71000
3、实现模型预测函数
- 目的:加载训练好的模型并测试效果
- 代码路径:llm_tuning/prompt_tasks/P_Tuning/inference.py
代码如下:
1 | import os |
- 结果展示
1 | { |