基于ChatGLM微调多任务实战
基于ChatGLM微调多任务实战
1. 项目介绍【理解】
1.1. 项目简介
LLM(Large Language Model)通常拥有大量的先验知识,使得其在许多自然语言处理任务上都有着不错的性能。但,想要直接利用 LLM 完成一些任务会存在一些答案解析上的困难,如规范化输出格式,严格服从输入信息等。因此,在这个项目中我们对大模型 ChatGLM-6B 进行 Finetune,使其能够更好的对齐我们所需要的输出格式。
1.2. ChatGLM-6B模型
1.2.1 模型介绍
ChatGLM-6B 是清华大学提出的一个开源、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。该模型使用了和 ChatGPT 相似的技术,经过约 1T 标识符的中英双语训练(中英文比例为 1:1),辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答(目前中文支持最好)。
相比原始Decoder模块,ChatGLM-6B模型结构有如下改动点:
- embedding 层梯度缩减:为了提升训练稳定性,减小了 embedding 层的梯度。梯度缩减的效果相当于把 embedding 层的梯度缩小了 10 倍,减小了梯度的范数。
- layer normalization:采用了基于 Deep Norm 的 post layer norm。
- 激活函数:替换ReLU激活函数采用了 GeGLU 激活函数。
- 位置编码:去除了绝对位置编码,采用了旋转位置编码 RoPE。
1.2.2 模型配置(6B)
| 配置 | 数据 |
|---|---|
| 参数 | 6.2B |
| 隐藏层维度 | 4096 |
| 层数 | 28 |
| 注意力头数 | 32 |
| 训练数据 | 1T |
| 词表大小 | 130528 |
| 最大长度 | 2048 |
1.2.3 硬件要求(官网介绍)
| 量化等级 | 最低GPU显存(推理) | 最低GPU显存(高效参数微调) |
|---|---|---|
| FP16(无量化) | 13GB | 14GB |
| INT8 | 10GB | 9GB |
| INT4 | 6GB | 7GB |
注意:显存的占用除了跟模型参数大小有关系外,还和文本支持最大长度有关
1.2.4 模型特点
- 优点
- 1.较低的部署门槛: INT4 精度下,只需6GB显存,使得 ChatGLM-6B 可以部署在消费级显卡上进行推理。
- 2.更长的序列长度: 相比 GLM-10B(序列长度1024),ChatGLM2-6B 序列长度达32K,支持更长对话和应用。
- 人类类意图对齐训练
- 缺点:
- 模型容量小,相对较弱的模型记忆和语言能力。
- 较弱的多轮对话能力。
1.3. 环境配置
1.3.1 基础环境配置:
本次环境依赖于AutoDL算力:https://www.autodl.com/home
- 操作系统: ubuntu22.04
- CPUs: 14 core(s),内存:100G
- GPUs: 1卡, A800, 80GB GPUs
- Python: 3.10
- Pytorh: 2.5.1
- Cuda: 12.4
- 价格:5.98元/小时
1.3.2 安装依赖包:
- 创建一个虚拟环境,您可以把
llm_env修改为任意你想要新建的环境名称:
1 | conda create -n llm_env python=3.10 |
- 激活新建虚拟环境
1 | conda activate llm_env |
注意: 如果激活失败,则先运行 conda init,然后退出终端,重新打开一个终端。
- 安装相应的依赖包:
1 | -- 成功切换到llm_env后安装 |
2
3
4
5
6
7
8
9
10
11
12
transformers==4.33
icetk
cpm_kernels
streamlit==1.18.0
matplotlib
datasets
accelerate>=0.20.3
packaging>=20.0
psutil
pyyaml
peft==0.3.0requirements.txt文件内容如上所示
1.3.3 预训练模型下载:
- 创建目录
1 | mkdir -p /root/autodl-tmp/llm_tuning/THUDM/chatglm-6b |
- 安装modelscope
1 | pip install modelscope |
- 下载chatglm-6b
1 | modelscope download --model ZhipuAI/ChatGLM-6B --local_dir ./ |
- python文件下载
如果configuration_chatglm.py、modeling_chatglm.py、quantization.py、tokenization_chatglm.py文件没有下载成功,则手动下载,然后添加到chatglm-6b的文件夹中。
下载位置:https://modelscope.cn/models/ZhipuAI/ChatGLM-6B/files
1.4. 项目架构
项目架构流程图:

项目代码架构图:

2.数据预处理【掌握】
- 本项目中对数据部分的预处理步骤如下:
- 查看项目数据集
- 编写Config类项目文件配置代码
- 编写数据处理相关代码
2.1 查看项目数据集
数据存放位置:llm_tuning/ptune_chatglm/data
data文件夹里面包含3个jsonl文档,分别为:mixed_train_dataset.jsonl、mixed_dev_dataset.jsonl、dataset.jsonl
2.1.1 train.jsonl
mixed_train_dataset.jsonl为训练数据集,因为我们本次项目同时进行「信息抽取+文本分类」两项任务,因此数据中混合了两种任务数据类型。举例展示如下:
- 信息抽取数据示例
- Instruction 部分告诉模型现在需要做「阅读理解」任务,Input 部分告知模型要抽取的句子以及输出的格式。
1
2
3
4{
"context": "Instruction: 你现在是一个很厉害的阅读理解器,严格按照人类指令进行回答。\nInput: 找到句子中的三元组信息并输出成json给我:\n\n九玄珠是在纵横中文网连载的一部小说,作者是龙马。\nAnswer: ",
"target": "```json\n[{\"predicate\": \"连载网站\", \"object_type\": \"网站\", \"subject_type\": \"网络小说\", \"object\": \"纵横中文网\", \"subject\": \"九玄珠\"}, {\"predicate\": \"作者\", \"object_type\": \"人物\", \"subject_type\": \"图书作品\", \"object\": \"龙马\", \"subject\": \"九玄珠\"}]\n```"
}- 文本数据示例
- Instruction 部分告诉模型现在需要做「阅读理解」任务,Input 部分告知模型要抽取的句子以及输出的格式。
1
2
3
4{
"context": "Instruction: 你现在是一个很厉害的阅读理解器,严格按照人类指令进行回答。\nInput: 下面句子可能是一条关于什么的评论,用列表形式回答:\n\n很不错,很新鲜,快递小哥服务很好,水果也挺甜挺脆的\nAnswer: ",
"target": "[\"水果\"]"
}
训练集中一共包含902条数据,每一条数据都分为
context和target两部分:
context部分是接受用户的输入。2.target部分用于指定模型的输出。在
context中又包括 2 个部分:
- Instruction:用于告知模型的具体指令,当需要一个模型同时解决多个任务时可以设定不同的 Instruction 来帮助模型判别当前应当做什么任务。
- Input:当前用户的输入。
2.1.2 dev.jsonl
- mixed_dev_dataset.jsonl为验证数据集,数据格式同train.jsonl。
如果想使用自定义数据训练,只需要仿照上述示例数据构建数据集即可。
2.2 编写项目Config类配置文件
代码路径:llm_tuning/ptune_chatglm/glm_config.py
config文件目的:配置项目常用变量,一般这些变量属于不经常改变的,比如:训练文件路径、模型训练次数、模型超参数等等
具体代码实现:
1 | import os.path |
2.3 编写数据处理相关代码
- 代码路径:llm_tuning/ptune_chatglm/data_handle
- data_handle文件夹中一共包含两个py脚本:data_preprocess.py、data_loader.py
2.3.1 data_preprocess.py
- 模型输入和标签的构建思路:
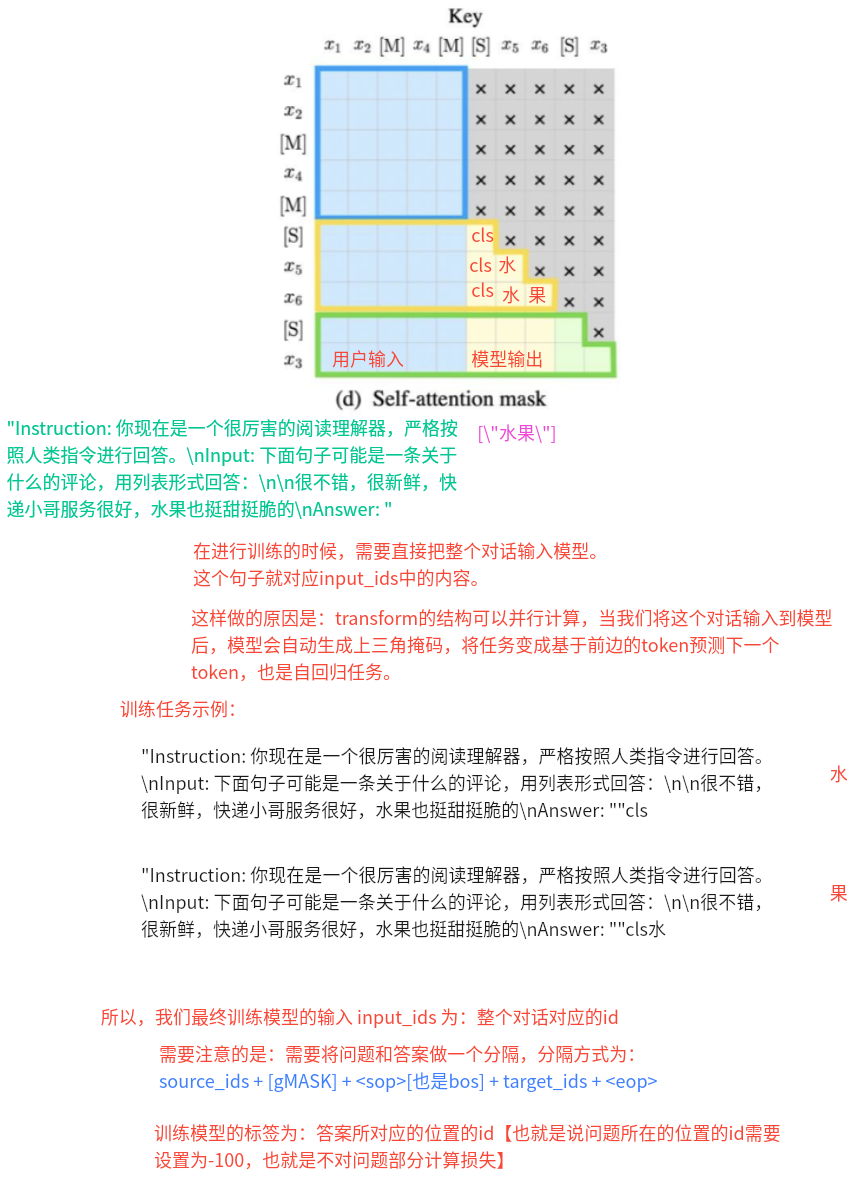
- 目的: 将样本数据转换为模型接受的输入数据
- 定义数据转换方法convert_example()
- 定义获取训练或验证数据最大长度方法get_max_length()
代码如下:
1 | import sys |
2.3.2 data_loader.py
目的:定义数据加载器
代码如下:
1 | from datasets import load_dataset |
- 打印结果:
1 | 902 |
2.3.3 代码上传
将写好的代码 ptune_chatglm 文件夹直接打包成zip文件。然后上传到autodl平台的 llm_tuning 文件夹下。
然后解压缩。
1 | cd /root/autodl-tmp/llm_tuning/ |
然后使用python xx.py的方式运行文件即可。
3.模型搭建与训练【掌握】
本项目中完成ChatGLM+LoRA模型搭建、训练及应用的步骤如下(注意:因为本项目中使用的是ChatGLM预训练模型,所以直接加载即可,无需重复搭建模型架构):
- 1.实现模型工具类函数
- 2.实现模型训练函数,验证函数
- 3.实现模型预测函数
3.0 前置知识
- ==lora模型配置:==
1 | # 如果使用lora方法微调 |
- ==lora调用:==
1 | loss = model( |
- ==lora模型保存:==
1 | def save_model(model, cur_save_dir: str): |
==ptuning的用法:==
1 | # 加载预训练模型的配置 |
3.1. 实现模型工具类函数
- 目的:模型在训练、验证、预测时需要的函数
- 代码路径:llm_tuning/ptune_chatglm/utils
- utils文件夹共包含1个py脚本:common_utils.py
3.1.1 common_utils.py
目的:定义数据类型转换类、分秒时之间转换以及模型保存函数。
脚本里面包含一个类以及两个函数:CastOutputToFloat、second2time()以及save_model()
- 定义CastOutputToFloat类
- 定义second2time()函数
- 定义save_model()
代码路径:llm_tuning/ptune_chatglm/utils/common_utils.py
代码如下:
1 | import torch |
3.2. 实现模型训练函数,验证函数
- 目的:实现模型的训练和验证
优化点:
==优化点1:==
model.config.use_cache = False
含义:关闭模型使用 past key/values(也叫 KV cache、attention cache)来重用之前层的注意力键值对。
效果:在训练时通常将其设为 False(尤其在启用 gradient checkpointing 时),因为缓存与 checkpointing 在某些实现上不兼容,会导致错误或额外内存/计算问题。把它设为 False 可以避免相关冲突。并且现在不再进行缓存,可以降低显存的占用。
在训练结束、用于部署/推理时应把 use_cache 恢复为 True 以利用 KV 缓存加速。
==优化点2:==
model.gradient_checkpointing_enable()
含义:开启==梯度检查点==。这是一个以牺牲计算时间换取显存的优化:前向时只保存一部分激活(checkpoints),在反向传播时对未保存的部分重新做一次(或多次)前向计算以得到梯度。
效果:==显存减低,训练速度变慢。==
==优化点3:==
model.enable_input_require_grads()
含义:允许把梯度“传到”输入层或做对输入嵌入的直接优化(例如 prompt tuning、微调 embedding、或某些 adapter/PEFT 的实现里需要)。
==优化点4:==
直接降低预训练模型的精度:
1 | # model.half()将模型数据类型从默认的float32精度转换为更低的float16精度,减少内存 |
混合精度训练:
1 | # autocast是PyTorch中一种混合精度的技术,可在保持数值精度的情况下提高训练速度和减少显存占用。 |
代码:
代码路径:llm_tuning/ptune_chatglm/train.py
脚本里面包含两个函数:model2train()和evaluate_model()
代码如下:
1 | import sys |
- 输出结果:

3.3. 实现模型预测函数
- 目的:加载训练好的模型并测试效果
- 代码路径:llm_tuning/prompt_tasks/ptune_chatglm/inference.py
具体代码:
1 | import sys |
- 结果展示
