基于GPT2的医疗问诊机器人
Created|Updated
|Post Views:
基于GPT2的医疗问诊机器人
学习目标
- 理解医疗问诊机器人的开发背景.
- 了解企业中聊天机器人的应用场景
- 掌握基于GPT2模型搭建医疗问诊机器人的实现过程
1. 项目介绍【理解】
1.1 项目背景
- 本项目基于医疗领域数据构建了智能医疗问答系统,目的是为为用户提供准确、高效、优质的医疗问答服务。
1.2 环境准备
- python==3.10
- transformers==4.40.2
- torch==2.5.1+cu121
1.3 项目整体结构

整体代码结构:

2. 数据处理【实现】
2.1 数据介绍
- 数据存放位置:llm_tuning/Gpt2_Chatbot/data
- data文件夹中存有原始训练语料为train.txt。train.txt的格式如下,每段闲聊之间间隔一行,格式如下:
1 | 帕金森叠加综合征的辅助治疗有些什么? |
2.2 数据处理
- 目的:将中文文本数据处理成模型能够识别的张量形式,并将上述文本进行张量的转换
- 实现过程:
- 运行preprocess.py,对data/train.txt对话语料进行tokenize,然后进行序列化保存到data/train.pkl。train.pkl中序列化的对象的类型为List[List],记录对话列表中,每个对话包含的token。
2.2.1 配置文件
- 代码路径:llm_tuning/Gpt2_Chatbot/parameter_config.py
1 | import torch |
2.2.1 数据张量转换
- 步骤
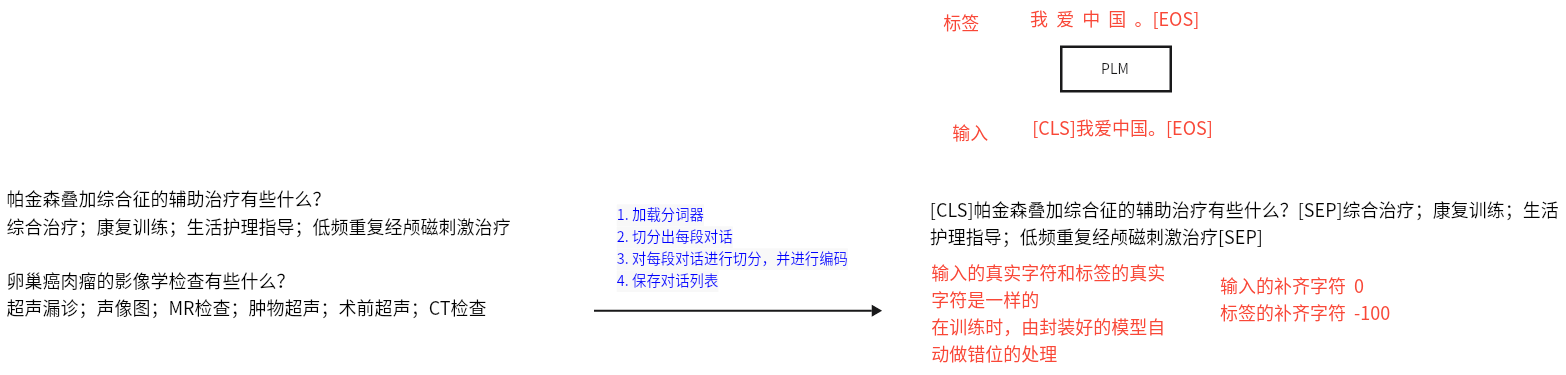
1 | 1. 加载分词器 |
==补充知识点:BertTokenizerFast==
一般在企业中,使用BertTokenizerFast比BertTokenizer要更多一些。原因:速度更快,并且提供了 字节级别精确对齐 的 offset mapping(可以知道 token 对应原始文本的字符位置
BertTokenizerFast的加载方式:
- 第一种:使用预训练模型进行加载
- 第二种:直接使用词表进行加载
代码路径:llm_tuning/Gpt2_Chatbot/data_preprocess/preprocess.py
1 | from transformers import BertTokenizerFast, BertTokenizer |
2.2.2 获取dataloader
(1)封装Dataset对象
- 代码路径:llm_tuning/Gpt2_Chatbot/data_preprocess/dataset.py
1 | from torch.utils.data import Dataset # 导入Dataset模块,用于定义自定义数据集 |
(2)封装DataLoader对象
==注意:使用pad_sequence做补齐,input_ids用0补齐,而labels用-100补齐!==
1 | input_ids = rnn_utils.pad_sequence(batch, batch_first=True, padding_value=0) |
- 代码路径:/home/user/ProjectStudy/Gpt2_Chatbot/data_preprocess/dataloader.py
1 | import torch.nn.utils.rnn as rnn_utils # 导入rnn_utils模块,用于处理可变长度序列的填充和排序 |
3. 模型搭建【理解】
3.1 模型架构介绍

模型架构解析:
- 输入层:词嵌入层:WordEmbedding +位置嵌入层:PositionEmbedding
- 中间层:Transformer的Decoder模块—12层
- 输出层:线性全连接层
模型主要参数简介(详见模型的config.json文件):
- n_embd: 768
- n_head: 12
- n_layer: 12
- n_positions: 1024
- vocab_size: 13317
3.2 GPT2模型准备
- 本次项目使用GPT2的预训练模型,因此不需要额外搭建Model类,下面代码是如何直接加载使用GPT2预训练模型
- 代码示例:
1 | from transformers import GPT2LMHeadModel, GPT2Config |
- 如果使用第二种方式,需要配置模型的参数
位置:llm_tuning/Gpt2_Chatbot/config/config.json
1 | { |
4. 模型训练和验证【掌握】
- 主要代码

代码位置
训练主函数:llm_tuning/Gpt2_Chatbot/train.py
辅助工具类:llm_tuning/Gpt2_Chatbot/functions_tools.py
- ==模型加载==
1 | # 根据参数决定模型的创建方式 |
- ==模型调用==
1 | # 如果对模型输入不仅包含input还包含标签,那么得到结果直接就有loss值。其中模型内部会把 logits/labels 做位移对齐(labels 通常可以等于 input_ids, 模型内部会把 logits[..., :-1, :] 与 labels[..., 1:] 对齐计算损失),并对被标为 -100 的 label 忽略不计。 |
- ==训练技巧==
==(1)学习率预热==
1 | ''' |
==(2)梯度累积==
作用:可以在显存不足的时候,训练多个批次后,再进行参数更新。这样可以缓解模型过拟合。
使用方式:
1 | outputs = model(input_ids, labels=labels) |
==(3)梯度裁剪==
1 | ''' |
- trian.py代码解析
1 | import torch |
- functions_tools.py代码解析
1 | import torch |
5. 模型预测(人机交互)【理解】
- 使用训练好的模型,进行人机交互,输入Ctrl+Z结束对话之后,聊天记录将保存到sample目录下的sample.txt文件中。
思路:

代码位置:llm_tuning/Gpt2_Chatbot/interact.py
1 | import os |
6. 基于Flask框架web开发【了解】
- 对interact.py进行调整, 去除while无限循环,由前端保存history,只需要对传入的句子进行预测即可。
代码位置:llm_tuning/Gpt2_Chatbot/flask_predict.py
1 | import os |
- 基于Flask框架的web后端接口
这部分可以用大模型生成,写好提示词即可。
1 | 使用大模型生成web前后端代码, 描述如下: |
代码位置:llm_tuning/Gpt2_Chatbot/app.py
1 | from flask import Flask, request, jsonify, render_template |
- web前端代码
代码位置:llm_tuning/Gpt2_Chatbot/templates/index.html
1 | <!DOCTYPE html> |
- 运行app.py文件, 效果如下:

Author: 甘虎文
Copyright Notice: All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles
2025-04-08
基于ChatGLM微调多任务
项目整体介绍:项目背景LLM拥有庞大的知识库,但是博而不精。在RAG项目中ChatModel,主要是用来回答用户的通用型知识和陪着聊天,但是LLM完成一些任务会存在一些答案解析上的困难,比如输出答案的格式:生成json格式、给生成的答案加水印等等。一般可以通过提示词完成,但是提示词有缺点,比如用户问:把上一代产品和现在的芯片做一个对比图,大模型私有化部署后,不知道上一代产品是什么,你需要告诉它上一代产品是G250芯片,现在是G260芯片,RAG只能给大模型提供什么是B260芯片,以及相关参数知识。但不能解决大模型理解用户的习惯问题。微调能更懂用户(企业)的偏好。 微调和提示词的优缺点: 维度 🛠️ 微调 🎩 提示词工程 核心比喻 量身定制的专属司机 熟知你的习惯、路线和偏好,无需多言。 使用通用地图APP 功能强大,但每次都要重新输入目的地和设置偏好。 工作原理 改变模型“大脑”结构 通过训练数据更新模型权重,内化知识和规则。 给模型“临时指令” 通过精心设计的文字引导模型,不改变其底层参数。 优点 ✅ 高可靠性 & 一致性:形成“肌肉记忆”,输出稳...
2024-02-25
基于ChatGLM微调多任务实战
基于ChatGLM微调多任务实战1. 项目介绍【理解】 1.1. 项目简介LLM(Large Language Model)通常拥有大量的先验知识,使得其在许多自然语言处理任务上都有着不错的性能。但,想要直接利用 LLM 完成一些任务会存在一些答案解析上的困难,如规范化输出格式,严格服从输入信息等。因此,在这个项目中我们对大模型 ChatGLM-6B 进行 Finetune,使其能够更好的对齐我们所需要的输出格式。 1.2. ChatGLM-6B模型1.2.1 模型介绍ChatGLM-6B 是清华大学提出的一个开源、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。该模型使用了和 ChatGPT 相似的技术,经过约 1T 标识符的中英双语训练(中英文比例为 1:1),辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答(目前中文支持最好)。 相比原始Decoder模块,ChatGLM-6B模型结构有如下改动点: embedding 层梯度缩...
2025-01-27
lora微调笔记
微调笔记 分类: fine tuning 传统全量微调,(高质量微调) prompt tuning(提示词微调) 技术:指令微调 上下文学习 chain of thought(思维链) PET模型(Pattern-Exploiting Training) POFT方法:分成三种类型:(面向提示的微调) 全量微调(Full Fine-Tuning):模型所有参数都参与更新,包括预训练模型参数和下游任务层参数。如PET模型。 部分参数微调(Partial Fine-Tuning):只更新预训练模型中的一部分参数,比如高层 transformer block、某些 attention 层或特定模块,其余参数冻结。如Adapter Tuning。 仅提示参数微调(Prompt-Only Tuning):冻结原始预训练模型参数,只训练 prompt 参数。如P-tuning、Prompt Tuning等。 Soft Prompt及微调方法PEFT(参数高效微调) conda env export > /ptune_chatglm/...
2024-03-30
大模型微调的主要方式
大模型微调的主要方式【掌握】1、大模型Prompt-Tuning方法1.1 NLP任务四种范式 第一范式:基于传统机器学习模型 第二范式:基于深度学习 第三范式:基于预训练模型+fine-tuning 第四范式:预训练模型+Prompt+预测 1.2 Fine-Tuning(微调)Fine-Tuning基本思想:使用小规模的特定任务文本继续训练预训练语言模型。 Fine-Tuning问题: 所需的Fine-Tuning量取决于预训练语料库和任务特定语料库之间的相似性。如果两者相似,可能只需要少量的Fine-Tuning,如果两者不相似,则可能需要更多的Fine-Tuning,并且效果不明显。 成本高 Prompt-Tuning的基本思想:通过添加模板的方法将任务目标转化为与预训练目标相似的形式(如MLM),避免引入额外的参数的同时,最大化利用模型的预训练知识。 Prompt-Tuning主要解决传统Fine-Tuning方式的两个痛点: **降低语义偏差:**预训练任务主要以MLM为主,而下游任务则重新引入新的训练参数,因此两个阶段目标差异较大。因此需要解决Pre-Tra...
2024-01-19
新零售行业评价决策系统
新零售行业评价决策系统一、项目介绍【理解】1、项目背景 随着科技的迅速发展和智能设备的普及,AI技术在新零售行业中得到了广泛应用。其中 智能推荐系统 是AI技在新零售中最为常见且有效的应用之一。通过分析用户的购买历史、浏览行为以及喜好偏好,推荐系统可以根据个人特征给用户进行个性化商品推荐。这种个性化推荐不仅可以提高用户购买意愿,减少信息过载,还可以带来更高的用户满意度和销量。 在智能推荐系统中,文本分类的应用属于重要的应用环节。比如:某电商网站都允许用户为商品填写评论,这些文本评论能够体现出用户的偏好以及商品特征信息,是一种语义信息丰富的隐式特征。 相比于单纯的利用显式评分特征,文本信息一方面可以弥补评分稀疏性的问题,另一方面在推荐系统的可解释方面也能够做的更好。 因此,本次项目我们将 以”电商平台用户评论”为背景,基于深度学习方法实现评论文本的准确分类 ,这样做的目的是通过用户对不同商品或服务的评价,平台能够快速回应用户需求,改进产品和服务。同时,自动分类也为个性化推荐奠定基础,帮助用户更轻松地找到符合其偏好的商品。 2、评论文本分类实现方法2.1 传统的深度学习方法 目前实...