dify_tutorial
Dify介绍
定义:Dify 是一款开源的大语言模型(LLM) 应用开发平台。它融合了后端即服务(Backend as Service) 的理念,使开发者可以快速搭建生产级的生成式 AI 应用。
安装Dify
安装Dify所在的机器的最低配置:
CPU核数 >= 2 Core
RAM运行内存 >= 4GB
先安装WSL(Windows Subsystem for Linux),根据系统,可选执行
原因:dify依赖linux系统,如果是在linux系统上部署,比如Ubuntu,就不需要安装WSL
定义:WSL 本质上是 Windows 的一个功能组件/子系统,它让 Windows 具备了原生运行 Linux 程序的能力,同时提供了管理这个环境的工具集。
参考操作文档:https://learn.microsoft.com/zh-cn/windows/wsl/install
以管理员权限打开PowerShell,运行以下命令去安装WSL:
1 | wsl --install |
安装完成后,重启电脑 已完成配置
安装linux发行版ubuntu
1 | wsl.exe --install -d ubuntu |
意外情况:如果安装过程停在 0.0%,请先执行:(一步完成:下载最新版并安装指定发行版)
1 | wsl.exe --install --web-download -d ubuntu |
cmd 检查正在运行的WSL的版本:(可选操作)
1 | wsl.exe --list --verbose |
如果需要下载其他的linux发行版,请输入命令:(将dis变量替换成需要安装的发行版本)
1 | wsl.exe --install [Distribution] |
可用linux发行版列表查看命令:
1 | wsl.exe --list --online |
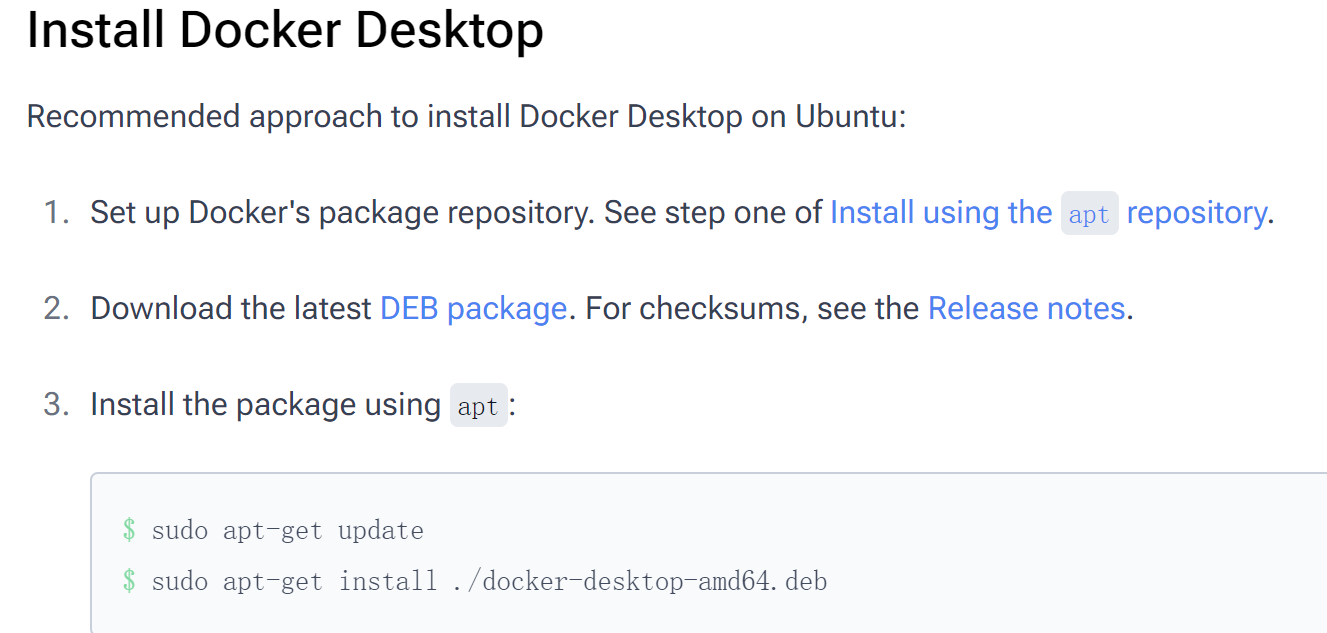
安装Docker Desktop
linux服务器分步骤式下载:https://docs.docker.com/desktop/setup/install/linux/ubuntu/
下载Docker desktop:
下载适合windows的Docker desktop安装包:https://www.docker.com/products/docker-desktop/
点击安装文件,安装完成后重启计算机
运行cmd,验证Docker是否安装成功
1 | docker --version |
配置docker compose文件
安装dify环境
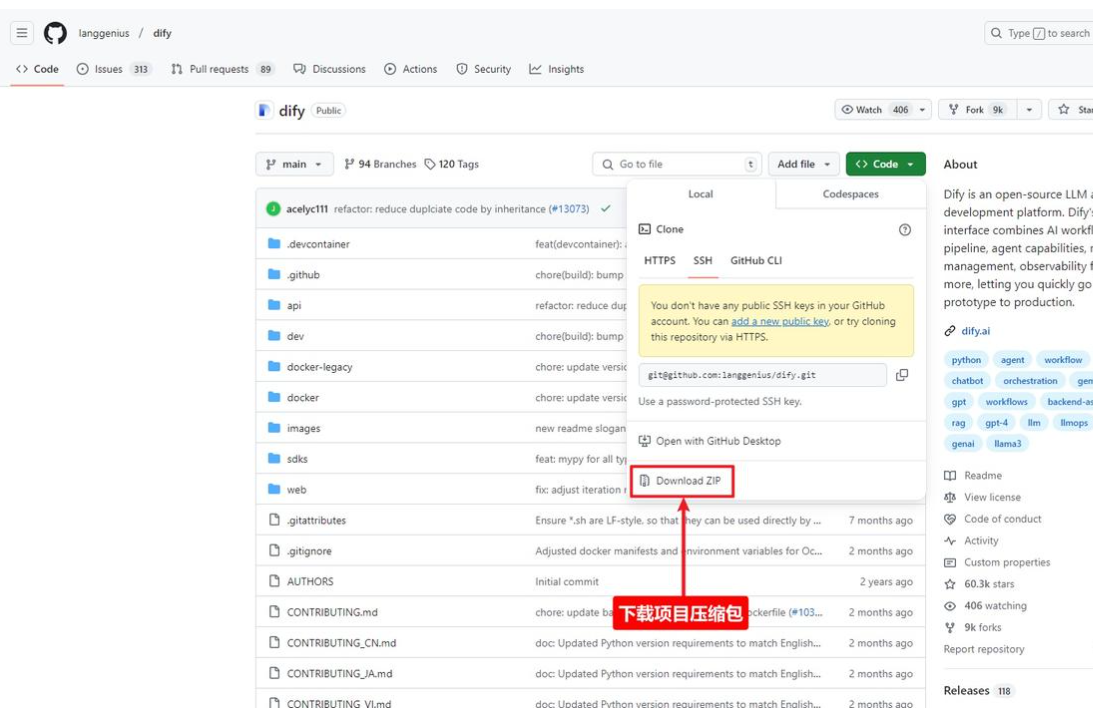
下载dify项目压缩包
可以克隆也可以直接下载
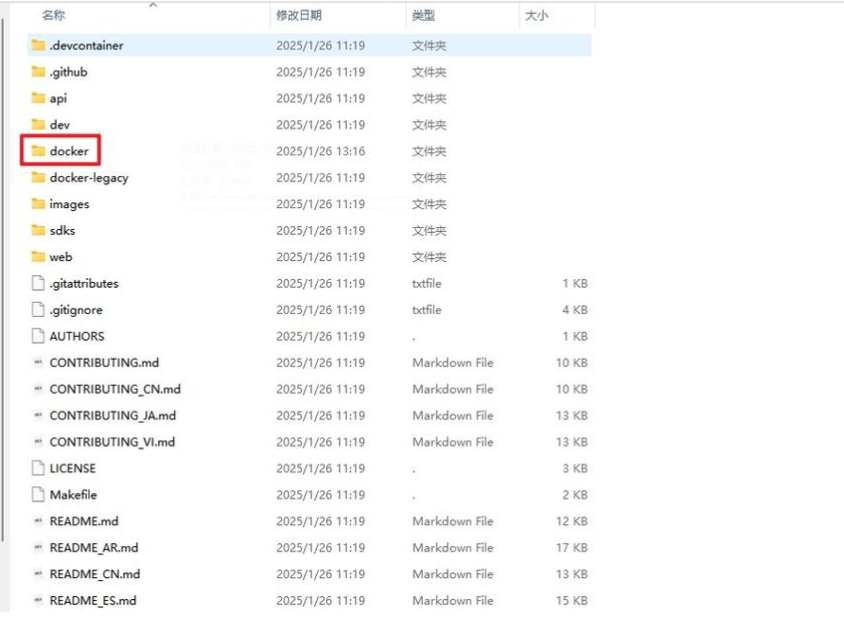
进入项目根目录找到docker文件夹
.env文件重命名
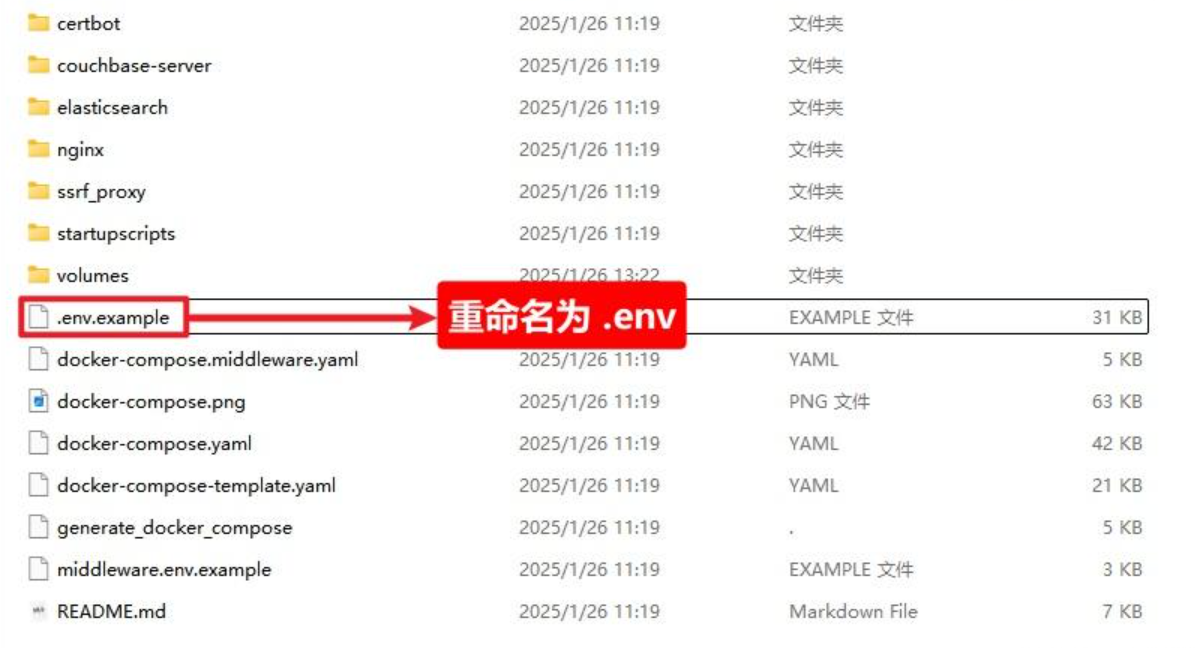
右键打开命令行
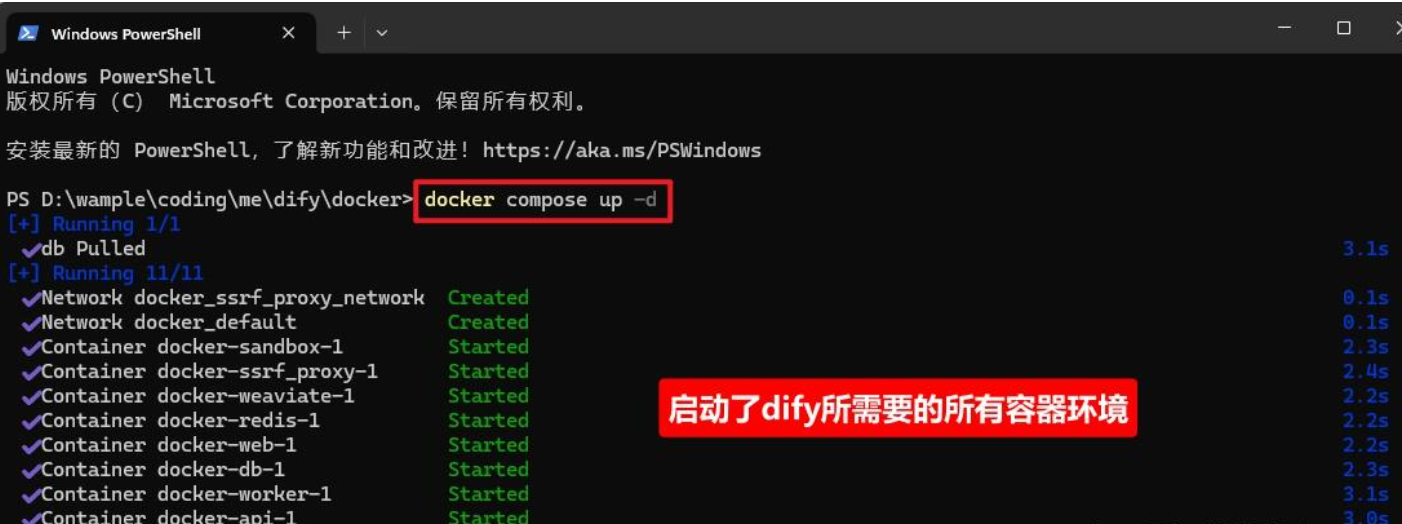
运行docker环境
1 | docker compose up -d |
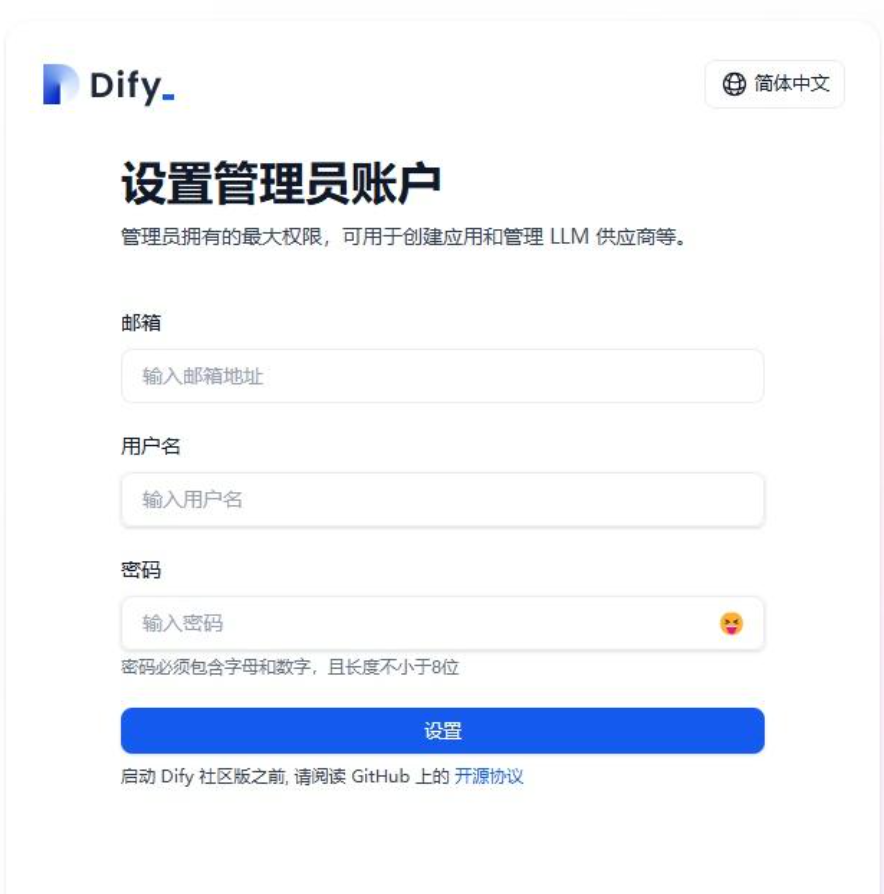
启动dify
在浏览器地址栏输入即可安装:
1 | http://127.0.0.1/install |
首次登录需进行注册:
dify的主界面如下所示:
大模型接入
大模型分三类:
1、推理模型:模型根据用户问题,给出回答,就是用的推理模型。
2、embedding模型:在知识库中,分块的文档转向量和用户query向量化都是用的embedding模型
3、语音转文字模型:在对话型应用中,将语音转文字用的就是该类型的模型
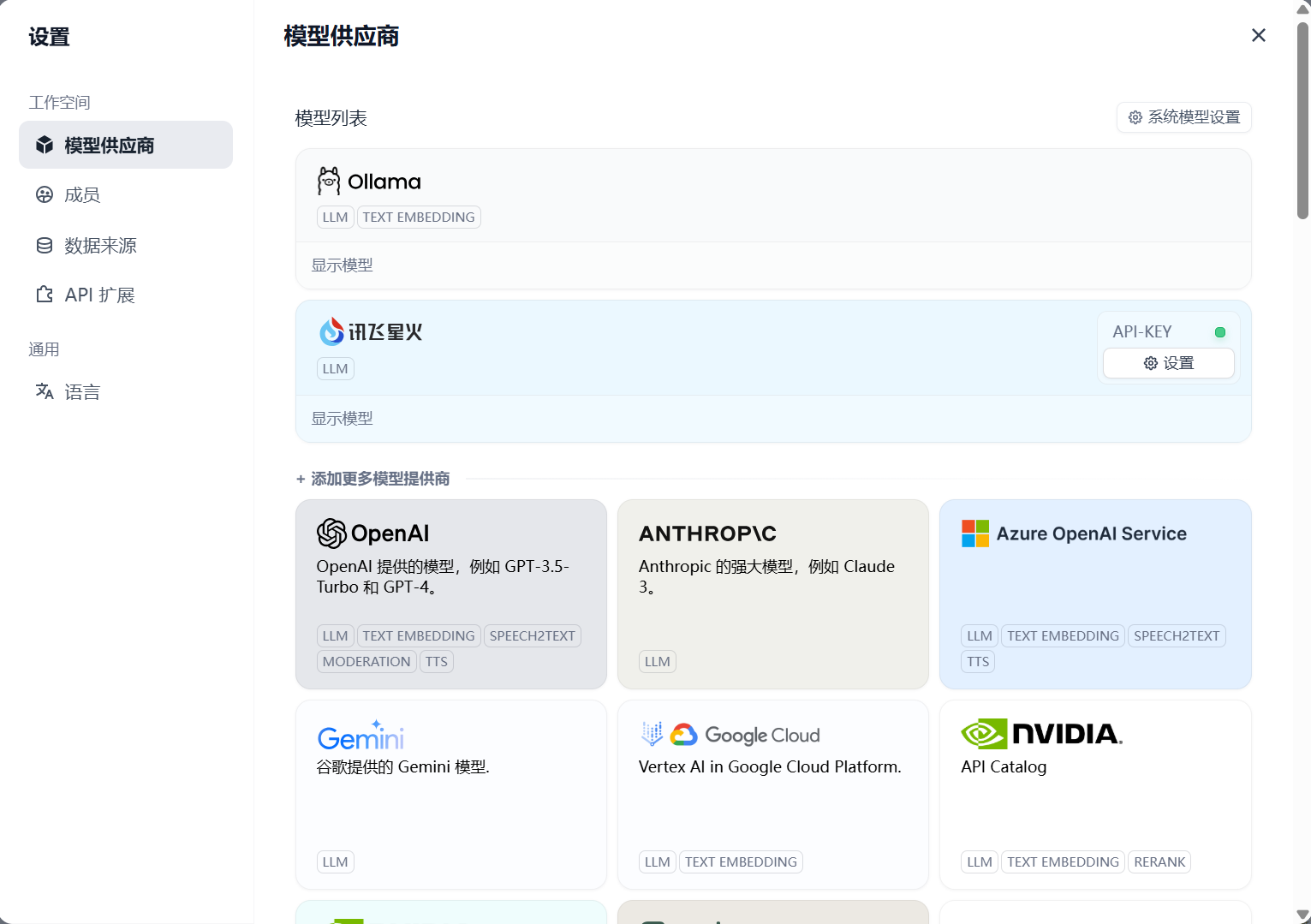
大模型接入
Dify页面–>点击头像–>设置–>模型供应商中设置要接入的模型
随便创建一个工作流,引用大模型
应用类型
dify提供了五种应用类型:
初级版:
聊天助手:基于LLM构建对话式交互的助手
文本生成应用:面向文本生成类任务的助手,例如写故事,文本分类、翻译等
Agent:能够分解任务、推理思考、调用工具的对话式智能助手
进阶版:
对话流chatflow:适用于定义等复杂流程的多轮对话场景,具有记忆功能的应用编排方式
工作流workflow:适用于自动化、批处理等单轮生成类任务的场景的应用编排方式
工作流(chatflow、workflow)
定义
工作流通过将复杂的任务分解成较小的步骤(节点)降低系统复杂度,减少了对提示词技术的依赖和对模型推理能力的依赖,提高了LLM应用面向复杂任务的性能,提升了系统的可解释性、稳定性和容错性
Dify工作流分为两种:
chatflow:面向对话类情景,包括客户服务、语义搜索、以及其他需要在构建响应进行多步逻辑的对话式应用程序
workflow:面向自动化和批处理情景,适合高质量翻译、数据分析、内容生成、电子邮件自动化等应用程序。
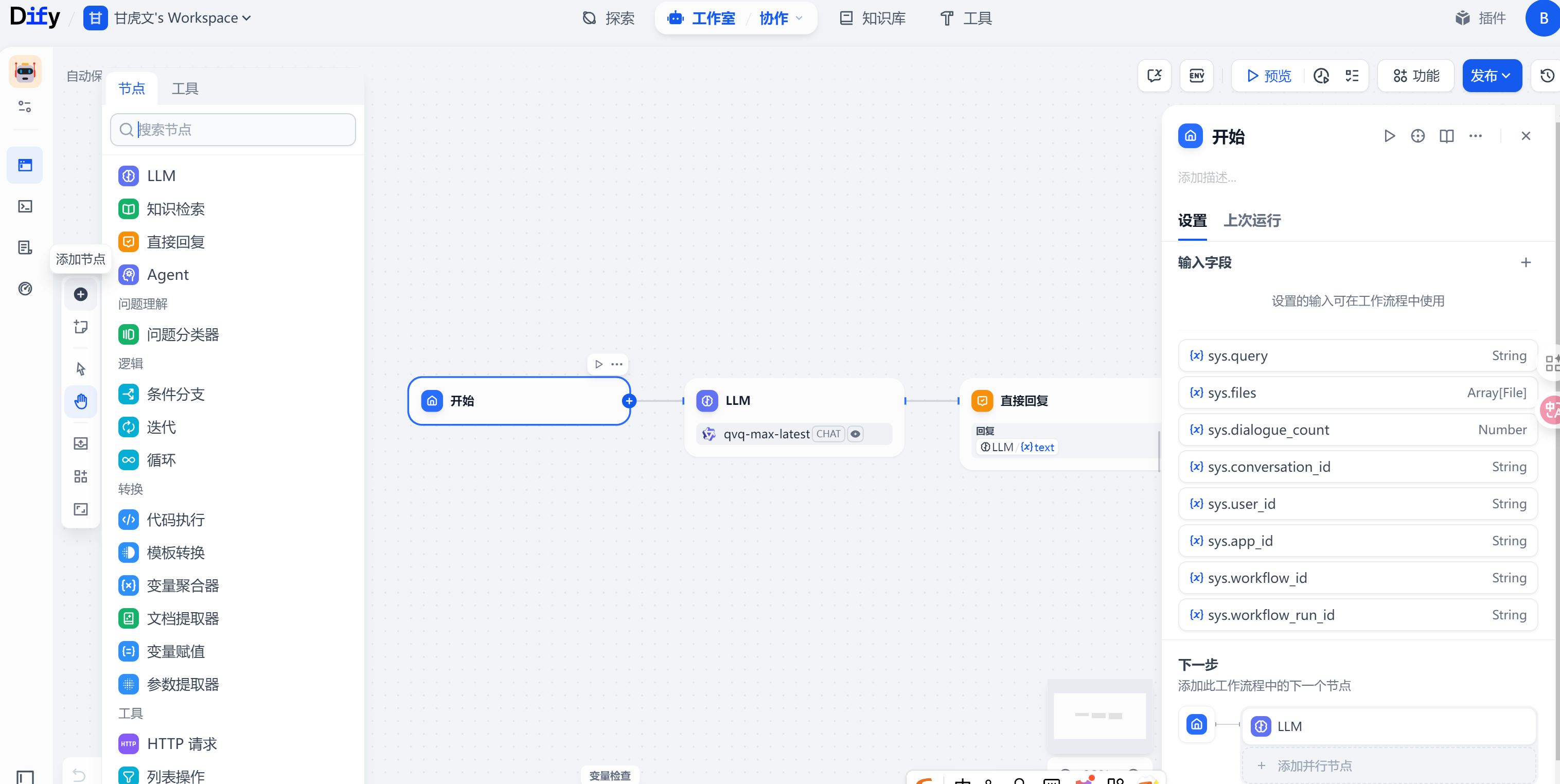
节点
它是工作流中的关键构成,通过连接不同功能的节点,执行工作流的一系列操作
新建一个空白应用,填写名称,点击创建,选择节点,在该节点后添加新节点
知识库
开发者可以将企业内部文档、规范信息等内容上传到知识库进行结构化处理,供后续LLM检索查询
点击知识库–>创建知识库
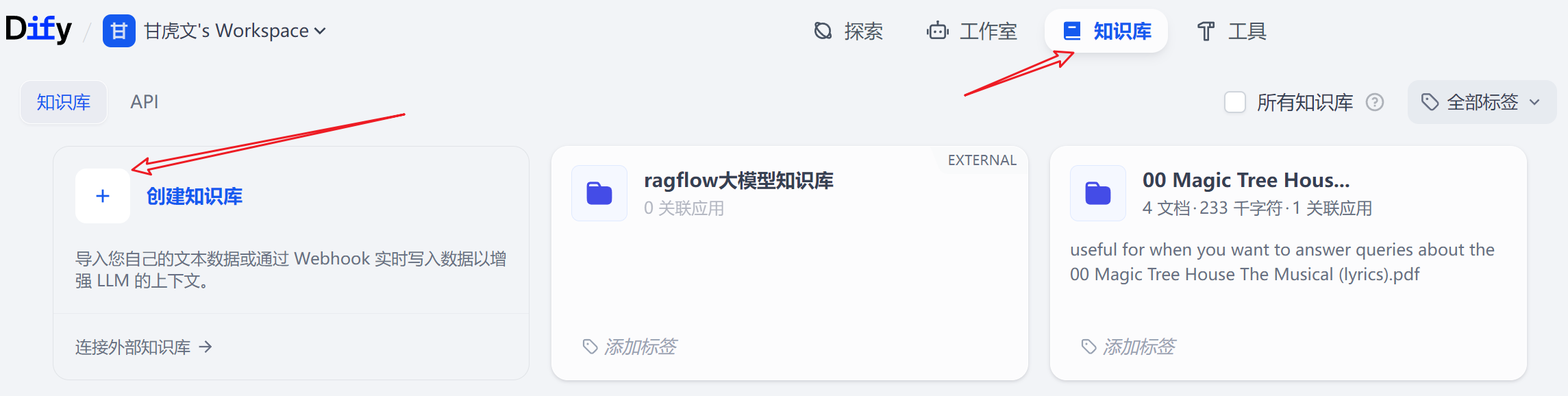
拖拽上传文件,或者创建一个空的知识库
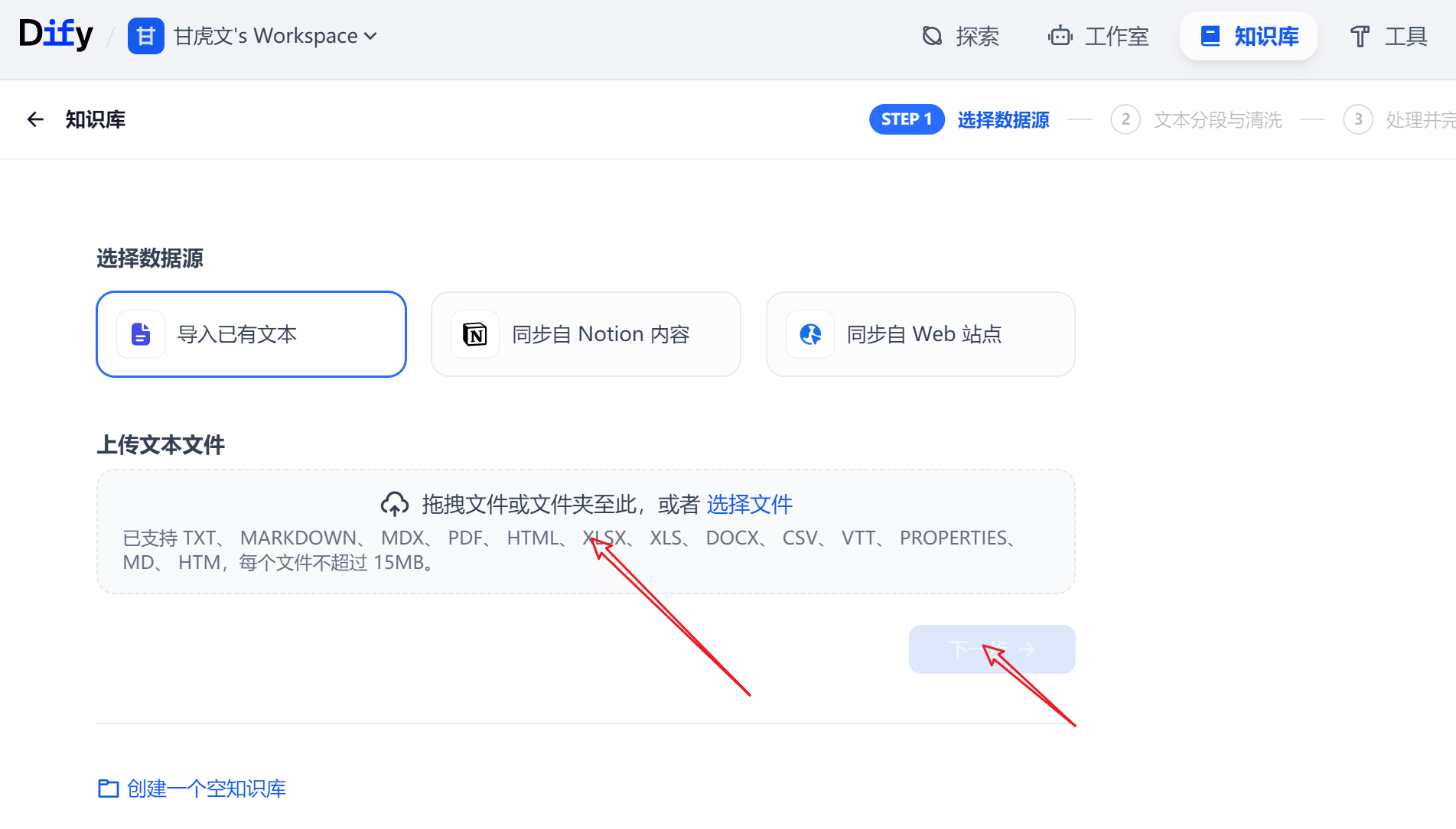
文本分块和清洗
分块设置
通用模式
文本分块(检索和召回的块是一样大的)
设置分段的标识符:\n\n,也可以是句号
设置分段的最大token数(chunk size):800
设置分段的重叠token长度(overlap):50(越大,表示文章连贯性越强)
数据清洗规则
把连续的空格、换行符和制表符替换掉(也就是多余的空格都删掉)
父子分块模式(建议选择)
文本分块时,子块用于检索,父块用于上下文召回
索引方式(选择是向量检索还是关键字检索)
高质量:embedding模型转文本为向量,做语义相似性计算,检索上下文**(建议选择)**
经济:关键字检索,参考tf-idf算法
检索设置
向量检索:(query和文档都转成向量,去对比相似性查询)
重排序模型设置:bge-rerank
设置召回的数量:TOP_K=3
全文检索:(提取关键词,做关键词匹配,底层是tf-idf算法,返回包含这些词汇的文本片段)
重排序模型设置:bge-rerank
设置召回的数量:TOP_K=3
混合检索:(建议选择)
权重设置:按照语义和关键词的比例进行权重分配,再对检索到的上下文重排序
RRF:根据语义相关匹配度进行再度排序,从而改进语义排序的结果
最优选择:
父子分块模式+向量作为索引(高质量检索)+混合检索
处理并完成
编辑知识库名称
等待文档嵌入处理完成
使用工作流
在任意浏览器打开链接,使用工作流