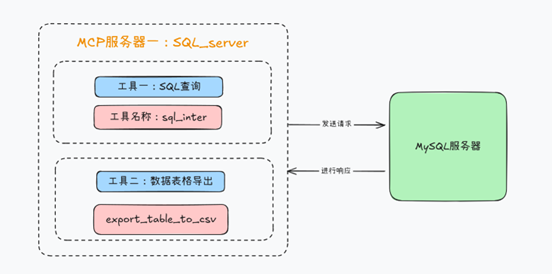
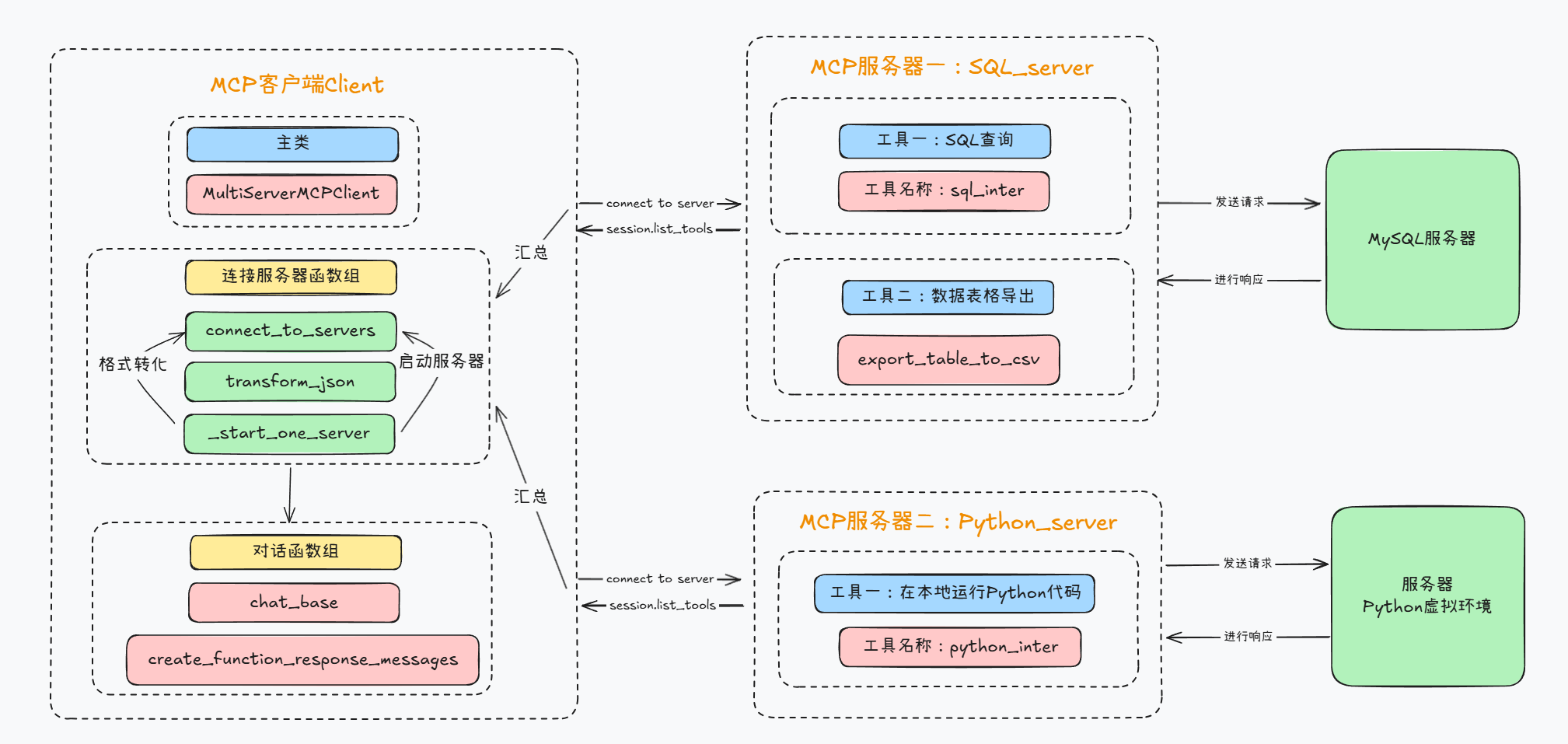
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
| import asyncio
import os
import json
from typing import Optional, Dict, Any, List, Tuple
from contextlib import AsyncExitStack
from openai import OpenAI
from dotenv import load_dotenv
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
load_dotenv()
class MultiServerMCPClient:
def __init__(self):
"""管理多个 MCP 服务器的客户端"""
self.exit_stack = AsyncExitStack()
self.openai_api_key = os.getenv("api_key")
self.base_url = os.getenv("base_url")
self.model = os.getenv("model_name")
if not self.openai_api_key:
raise ValueError("❌ 未找到 openai_api_key,请在 .env 文件中配置")
self.client = OpenAI(api_key=self.openai_api_key, base_url=self.base_url)
self.sessions: Dict[str, ClientSession] = {}
self.tools_by_session: Dict[str, list] = {}
self.all_tools: List[dict] = []
async def connect_to_servers(self, servers: dict):
"""
servers: {"weather": "weather_server.py", "rag": "rag_server.py"}
"""
for server_name, script_path in servers.items():
session = await self._start_one_server(script_path)
self.sessions[server_name] = session
resp = await session.list_tools()
self.tools_by_session[server_name] = resp.tools
for tool in resp.tools:
function_name = f"{server_name}_{tool.name}"
input_schema = getattr(tool, "inputSchema", None) or getattr(tool, "input_schema", None) or {}
self.all_tools.append({
"type": "function",
"function": {
"name": function_name,
"description": tool.description if hasattr(tool, "description") else "",
"input_schema": input_schema
}
})
self.all_tools = await self.transform_json(self.all_tools)
print("\n✅ 已连接到下列服务器:")
for name in servers:
print(f" - {name}: {servers[name]}")
print("\n汇总的工具:")
for t in self.all_tools:
print(f" - {t['function']['name']}")
async def transform_json(self, json2_data):
"""
将 {"type":"function","function":{"name":..,"description":..,"input_schema":{...}}}
转为保持同样外层但把 input_schema -> parameters
"""
result = []
for item in json2_data:
if not isinstance(item, dict) or "type" not in item or "function" not in item:
continue
old_func = item["function"]
if not isinstance(old_func, dict) or "name" not in old_func or "description" not in old_func:
continue
new_func = {
"name": old_func["name"],
"description": old_func["description"],
"parameters": {}
}
if "input_schema" in old_func and isinstance(old_func["input_schema"], dict):
old_schema = old_func["input_schema"]
new_func["parameters"]["type"] = old_schema.get("type", "object")
new_func["parameters"]["properties"] = old_schema.get("properties", {})
new_func["parameters"]["required"] = old_schema.get("required", [])
result.append({
"type": item["type"],
"function": new_func
})
return result
async def _start_one_server(self, script_path: str) -> ClientSession:
is_python = script_path.endswith(".py")
is_js = script_path.endswith(".js")
if not (is_python or is_js):
raise ValueError("服务器脚本必须是 .py 或 .js 文件")
command = "python" if is_python else "node"
server_params = StdioServerParameters(
command=command,
args=[script_path],
env=None
)
stdio_transport = await self.exit_stack.enter_async_context(stdio_client(server_params))
read_stream, write_stream = stdio_transport
session = await self.exit_stack.enter_async_context(ClientSession(read_stream, write_stream))
await session.initialize()
return session
def extract_tool_result(self, call_tool_result: Any) -> str:
data = getattr(call_tool_result, "data", None)
if data is not None:
try:
return json.dumps(data, ensure_ascii=False)
except Exception:
return str(data)
content = getattr(call_tool_result, "content", None)
if content:
parts: List[str] = []
for block in content:
text = None
if isinstance(block, dict):
text = block.get("text") or block.get("content") or str(block)
else:
text = getattr(block, "text", None) or getattr(block, "content", None)
if text is None:
text = str(block)
parts.append(text)
return "\n".join(parts)
return "工具执行无输出"
async def _call_openai_sync(self, /, *args, **kwargs):
return await asyncio.to_thread(self.client.chat.completions.create, *args, **kwargs)
async def chat_base(self, messages: list) -> Any:
"""
messages: list of dicts: {"role":..., "content":...}
返回 OpenAI response 对象(同步 response,但我们在线程里调用)
"""
response = await self._call_openai_sync(
model=self.model,
messages=messages,
tools=self.all_tools
)
while getattr(response.choices[0], "finish_reason", None) == "tool_calls":
messages = await self.create_function_response_messages(messages, response)
response = await self._call_openai_sync(
model=self.model,
messages=messages,
tools=self.all_tools
)
return response
async def create_function_response_messages(self, messages, response):
"""
解析 response 中的 tool_calls,调用 MCP 工具,并把工具结果加入消息序列
"""
messages.append(response.choices[0].message.model_dump() if hasattr(response.choices[0].message, "model_dump") else response.choices[0].message)
function_call_messages = response.choices[0].message.tool_calls or []
for function_call_message in function_call_messages:
tool_name = function_call_message.function.name
try:
tool_args = json.loads(function_call_message.function.arguments)
except Exception:
tool_args = getattr(function_call_message.function, "arguments", {}) or {}
function_response_raw = await self._call_mcp_tool(tool_name, tool_args)
messages.append(
{
"role": "tool",
"content": function_response_raw,
"tool_call_id": function_call_message.id,
}
)
return messages
async def process_query(self, user_query: str, messages: Optional[List[Dict[str, Any]]] = None) -> Tuple[str, List[Dict[str, Any]]]:
"""
处理单个用户查询并返回模型最终文本输出与更新后的消息历史。
- 将 user_query append 到 messages(若 messages 为 None 则新建)。
- 使用 chat_base() 来运行模型(chat_base 已处理 tool_calls 的循环)。
- 返回 (final_text, messages)
备注:返回 messages 以便外部(如 chat_loop)维护对话历史。
"""
if messages is None:
messages = []
messages.append({"role": "user", "content": user_query})
messages = messages[-20:]
response = await self.chat_base(messages)
assistant_msg = response.choices[0].message
final_text = getattr(assistant_msg, "content", None)
'''
在某些 SDK(或 Pydantic)实现里,message 可能是一个复杂的 Pydantic 对象或自定义对象,直接访问 .content 不一定存在或不可靠。很多这类对象都提供 model_dump()(或类似方法)把内部数据转换成 Python 原生 dict。
所以当直接取不到 content 时,试着把对象“摊平”成 dict,再从 dict 里取 content
'''
if final_text is None and hasattr(assistant_msg, "model_dump"):
md = assistant_msg.model_dump()
if isinstance(md, dict):
final_text = md.get("content")
else:
final_text = str(md)
if final_text is None:
try:
final_text = str(assistant_msg)
except Exception:
final_text = ""
if not messages or messages[-1].get("role") != "assistant":
assistant_entry = assistant_msg.model_dump() if hasattr(assistant_msg, "model_dump") else assistant_msg
messages.append(assistant_entry)
messages = messages[-40:]
return final_text, messages
async def _call_mcp_tool(self, tool_full_name: str, tool_args: dict) -> str:
parts = tool_full_name.split("_", 1)
if len(parts) != 2:
return f"无效的工具名称: {tool_full_name}"
server_name, tool_name = parts
session = self.sessions.get(server_name)
if not session:
return f"找不到服务器: {server_name}"
resp = await session.call_tool(tool_name, tool_args)
out = self.extract_tool_result(resp)
return out
async def chat_loop(self):
print("\n🤖 多服务器 MCP + Function Calling 客户端已启动!输入 'quit' 退出。")
messages: List[Dict[str, Any]] = []
while True:
query = await asyncio.to_thread(input, "\n你: ")
if query is None:
continue
query = query.strip()
if query.lower() == "quit":
break
try:
final_text, messages = await self.process_query(query, messages)
print(f"\nAI: {final_text}")
except Exception as e:
print(f"\n⚠️ 调用过程出错: {e}")
async def cleanup(self):
await self.exit_stack.aclose()
async def main():
servers = {
"write": "write_server.py",
"weather": "weather_server.py",
"SQLServer": "SQL_server.py",
"PythonServer": "Python_server.py"
}
client = MultiServerMCPClient()
try:
await client.connect_to_servers(servers)
await client.chat_loop()
finally:
await client.cleanup()
if __name__ == "__main__":
asyncio.run(main())
|