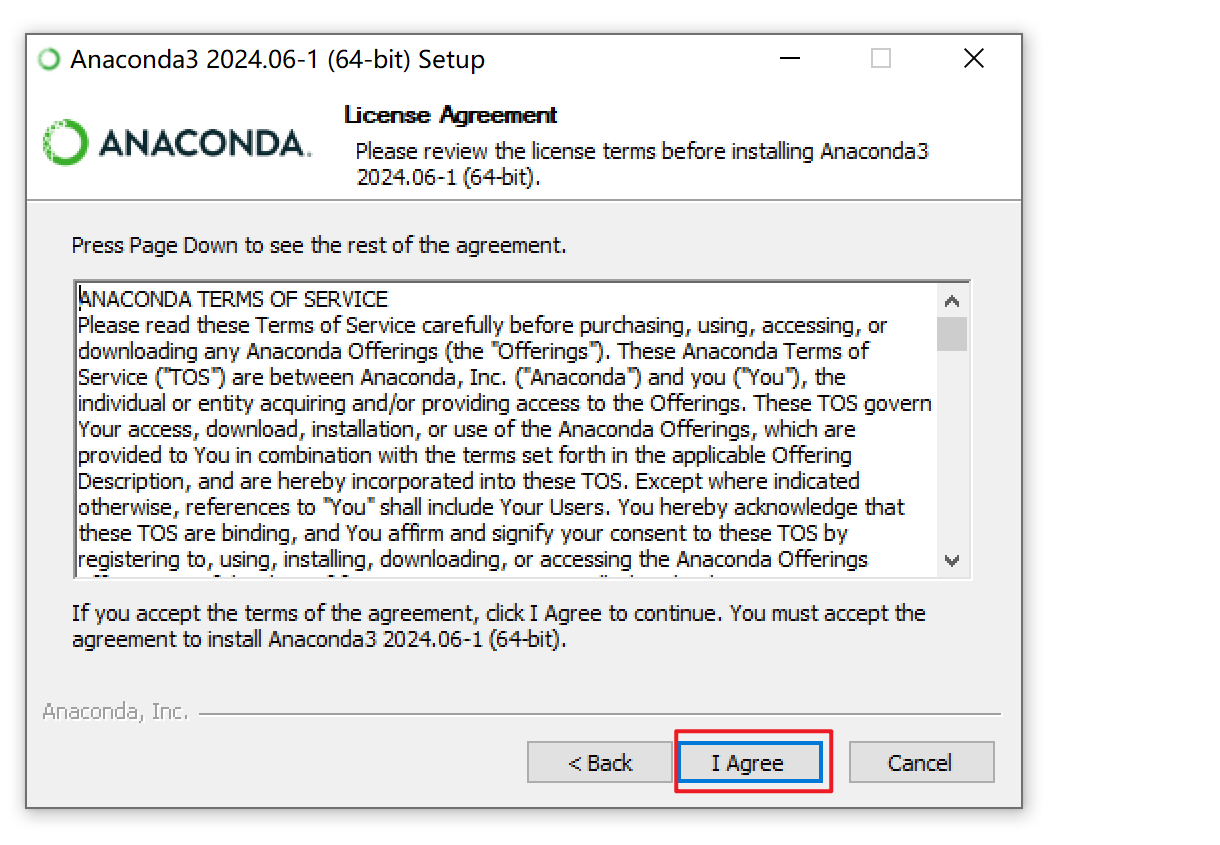
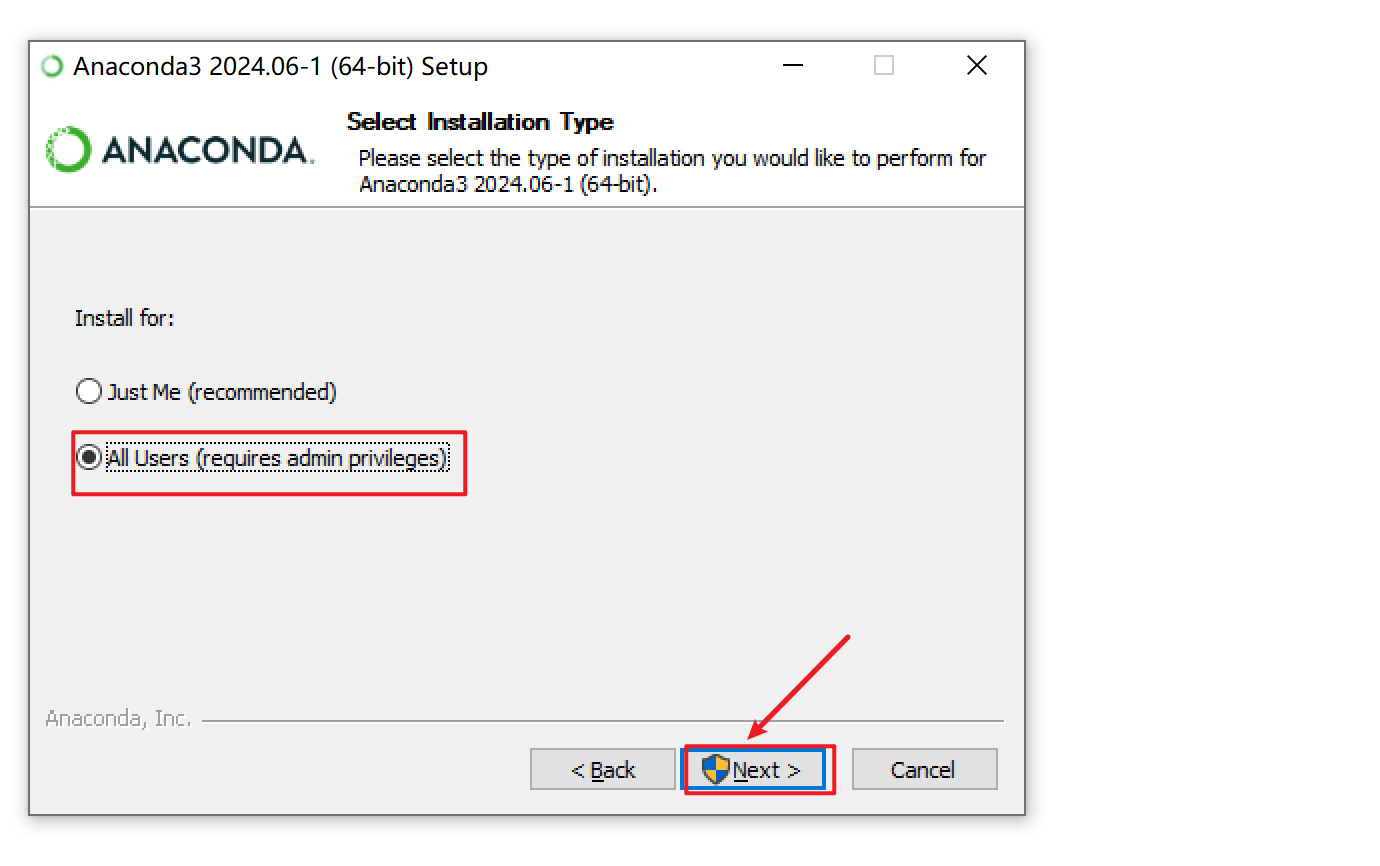
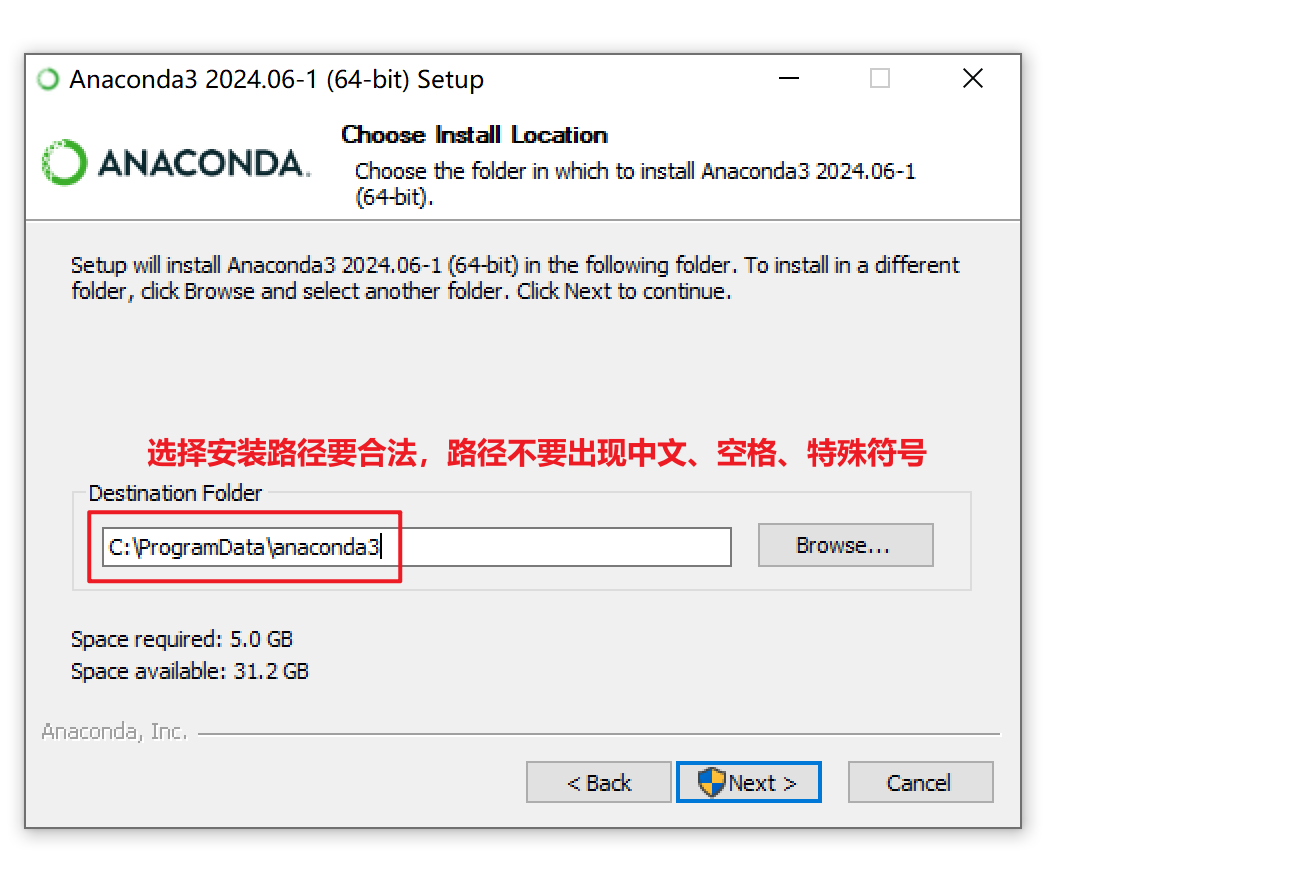
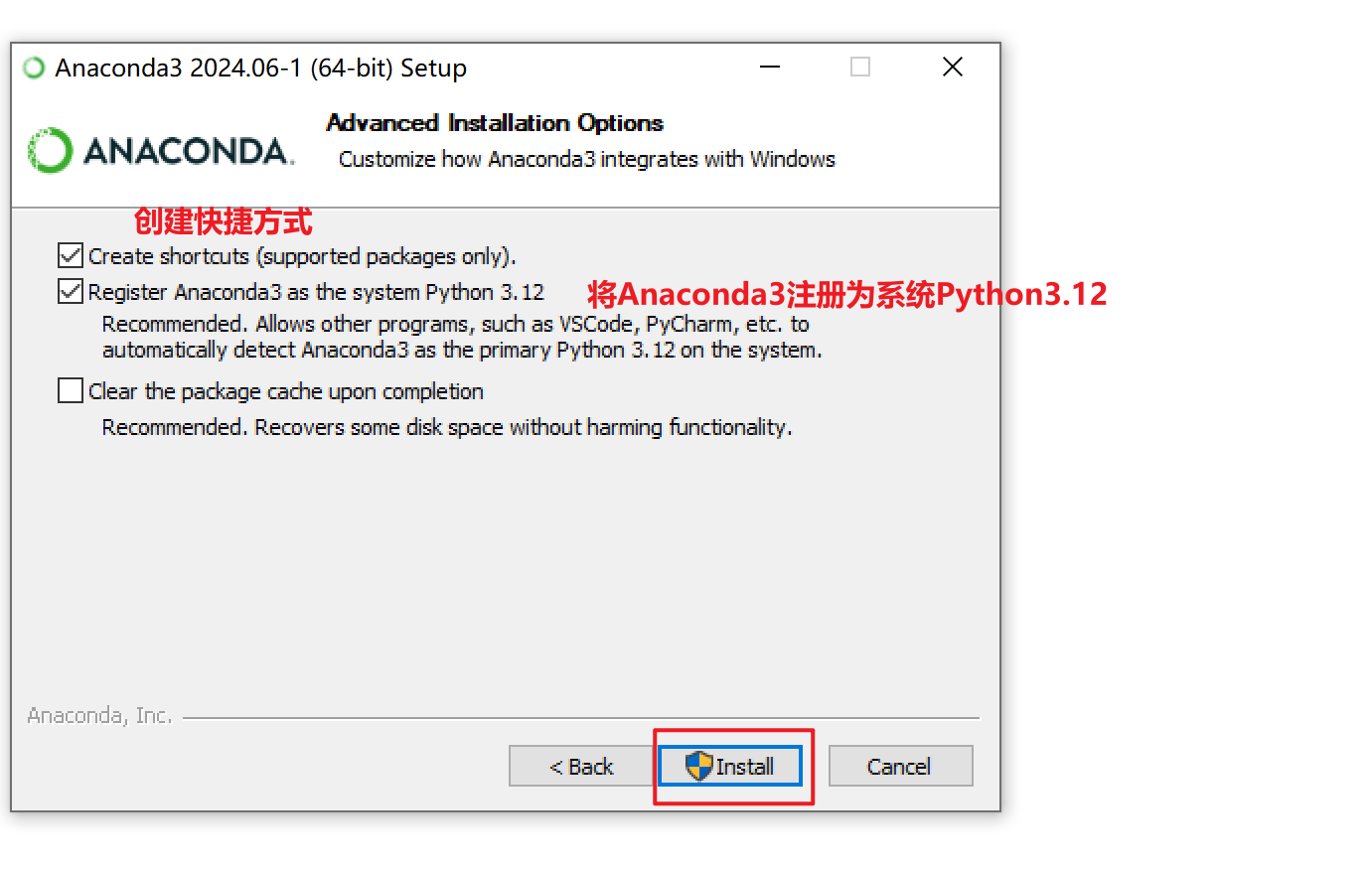
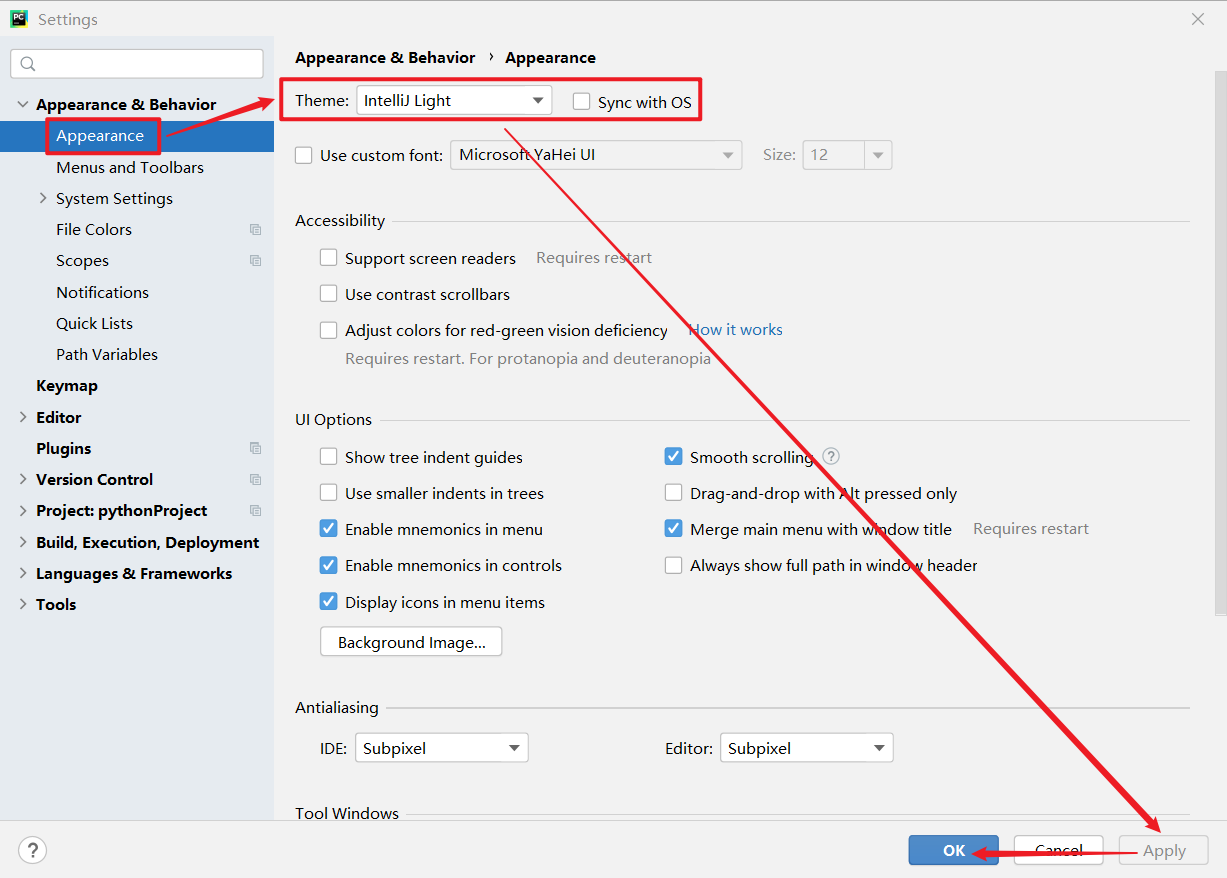
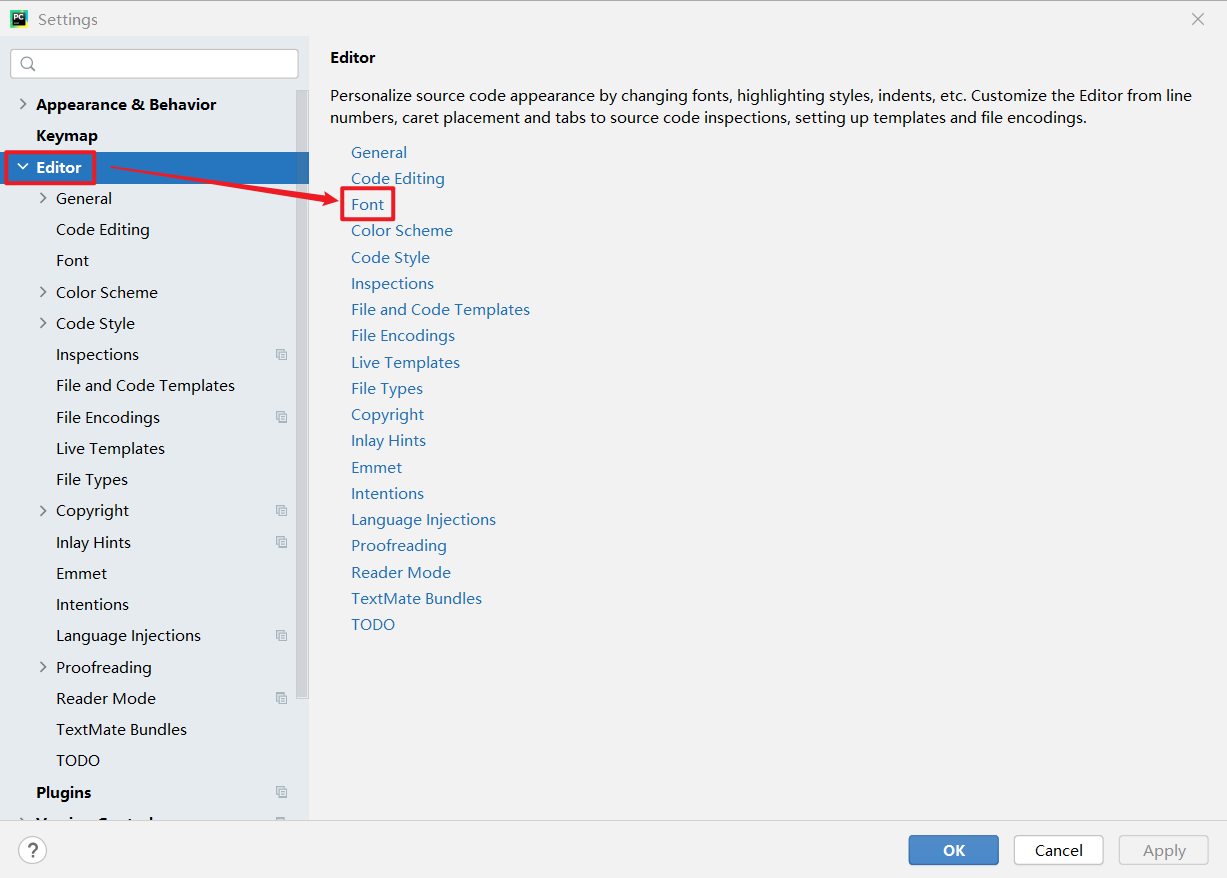
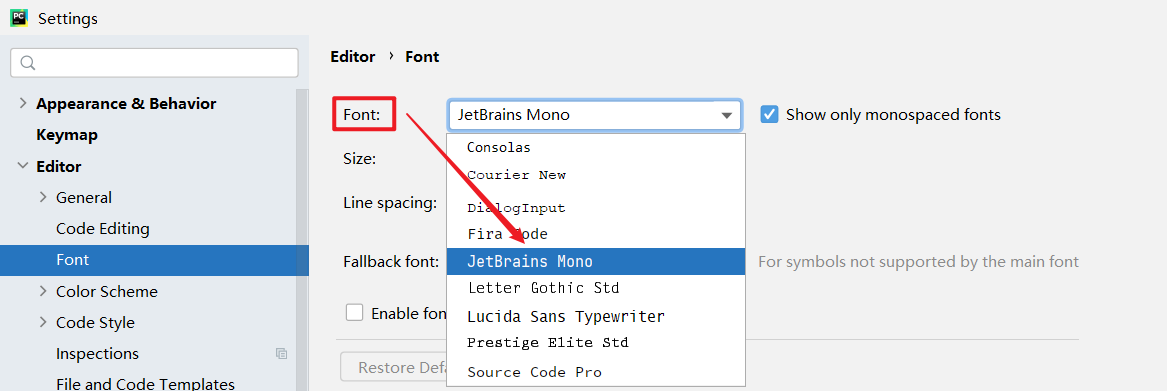
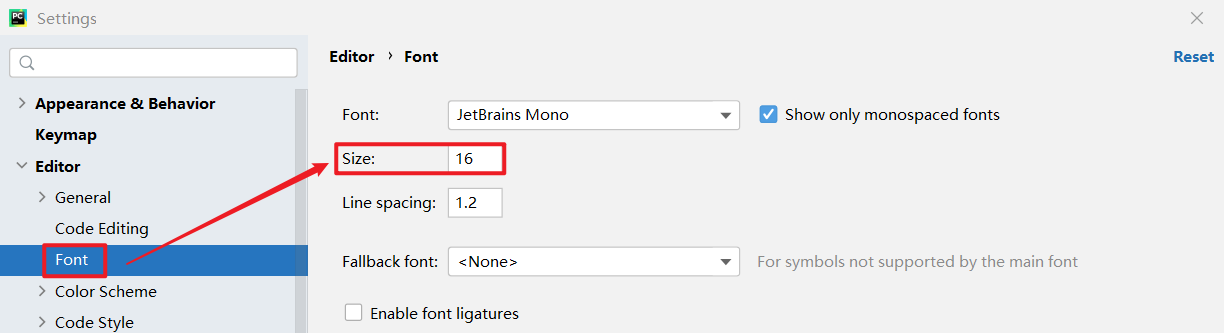
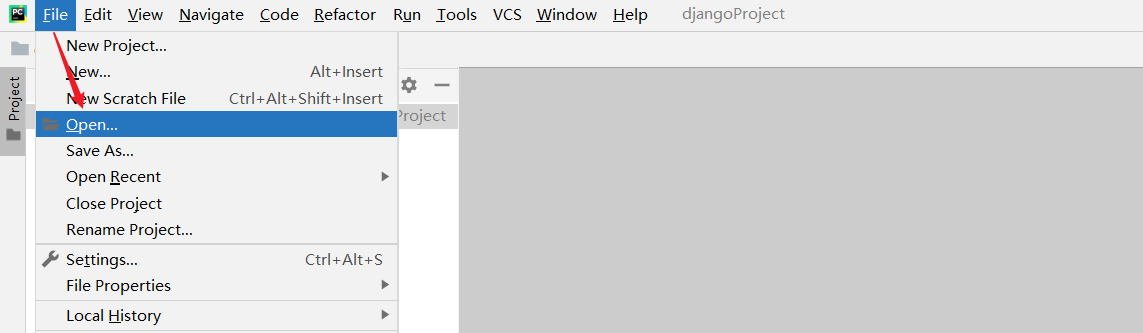
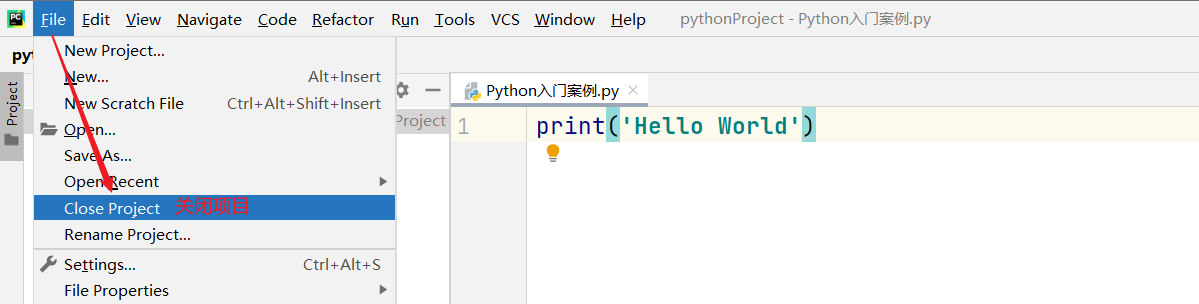
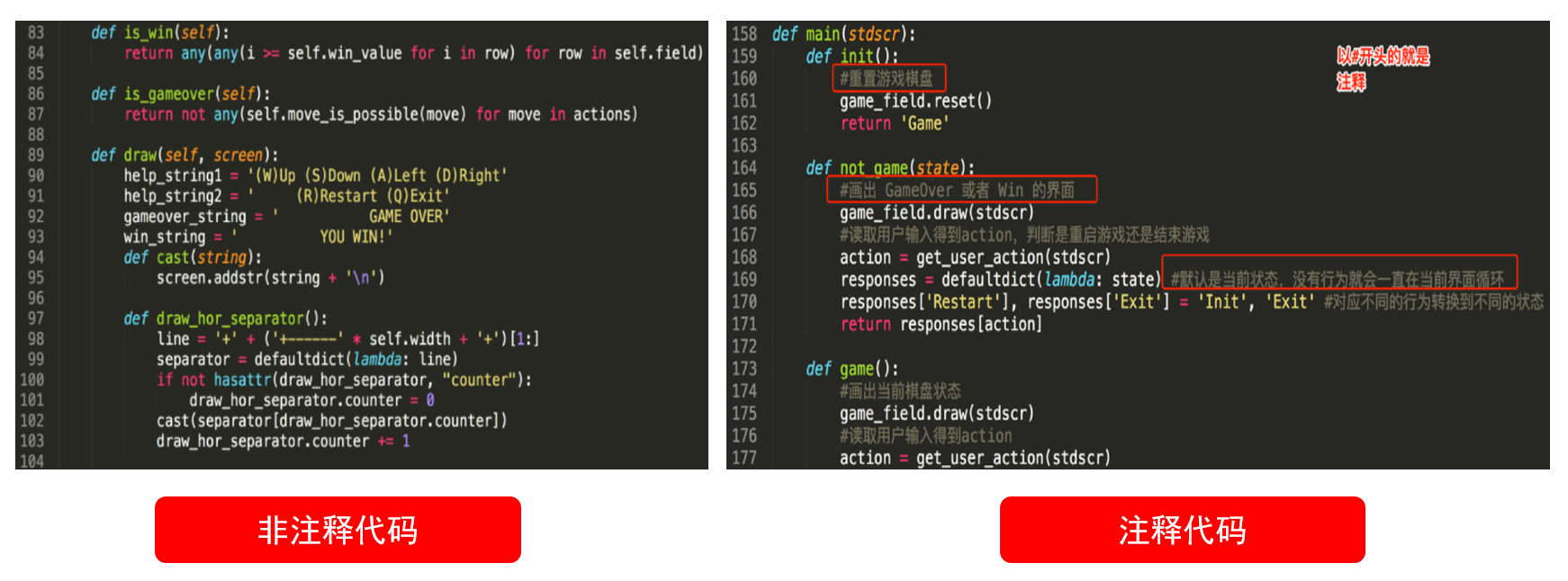
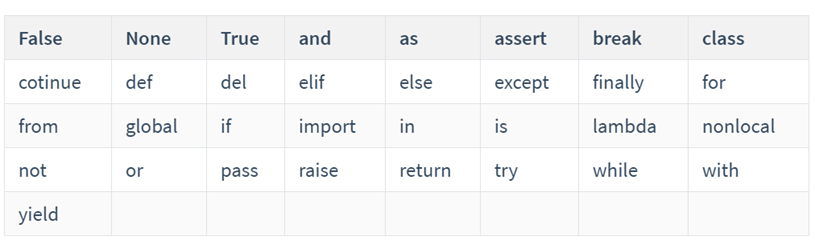
需要继承baseoutputparser,实现parse()方法,get format instructions()方法 解析大模型的输出,然后组织成想要的个数 提供格式指导给模型 处理空白和换行符,用冒号做split切分;返回一个字典 custom, 定义大模型输出的格式 from template(模版说明)
解析器:告诉大模型该怎么输出 get_fromat_instructions()
invoke(填充好提示词),最后通过结果解析器,调用parse方法
核心是实现parse方法。
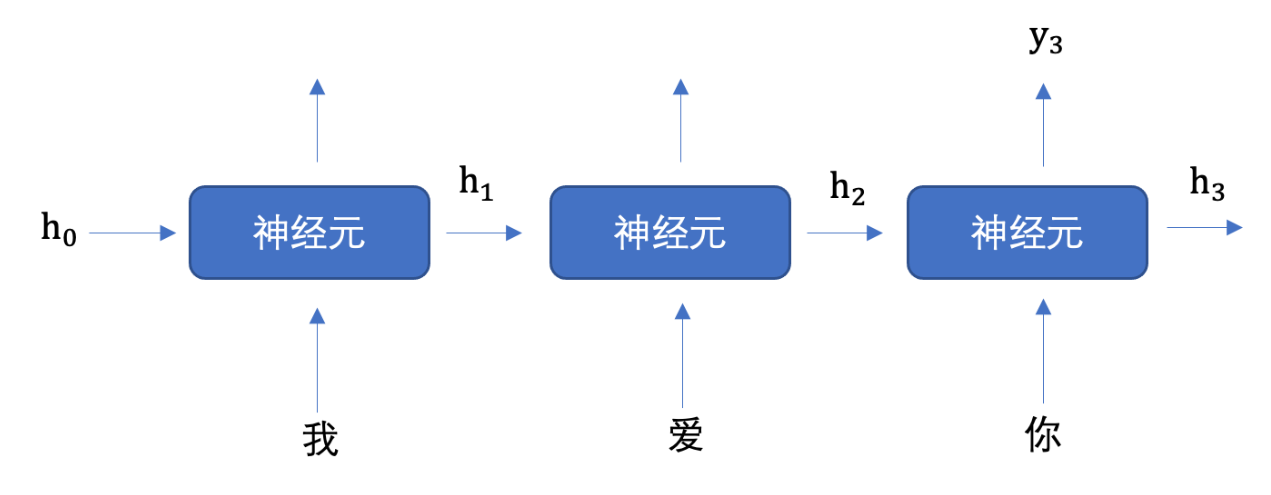
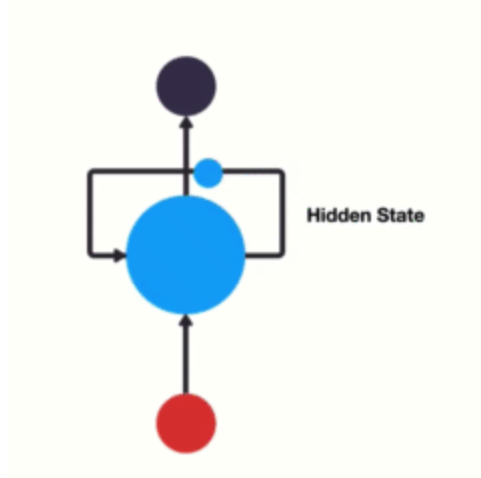
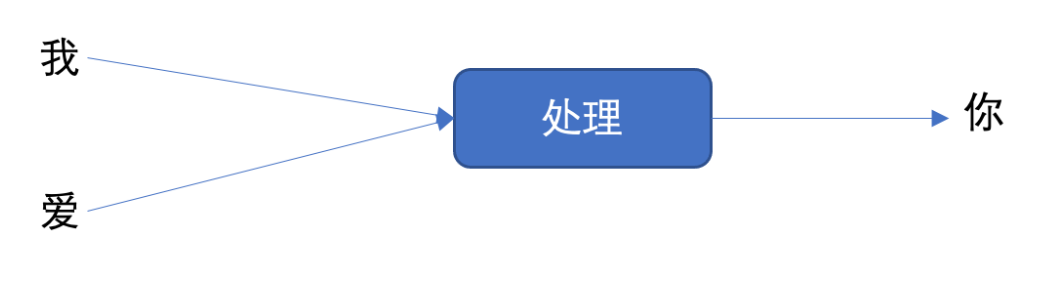
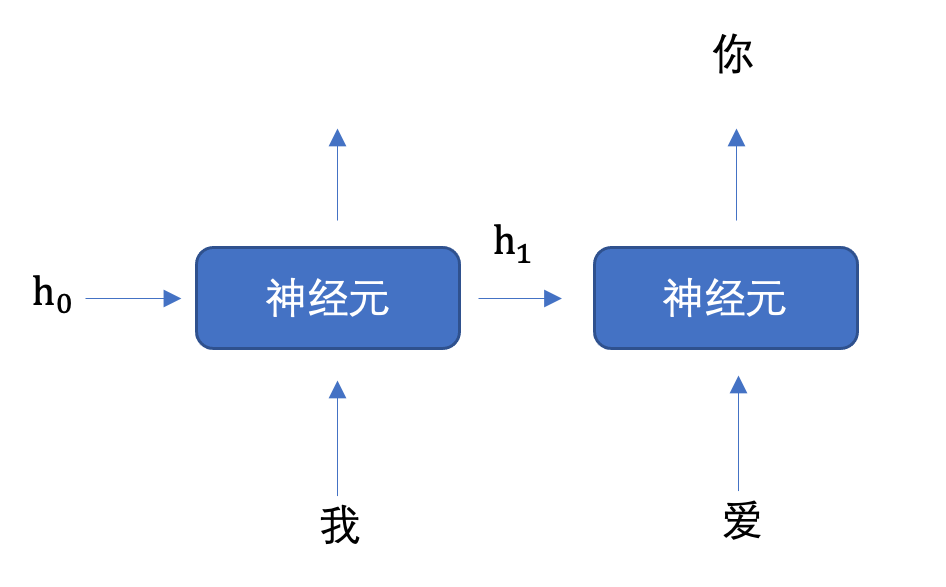
Memory
储存上下文,储存历史
langchain提供了memory组件:
ChatMessageHistory:只是简单存储
1 2 3 4 5 6
history = ChatMessageHistory() 添加用户消息 history.add_user_message('xxx') 添加大模型回复的消息 history.add_ai_message('xxx')
langchain.text.splitters import CharacterTextSplitter 创建分词器separator参数指的是分割的分隔符,chunk size指的是分割出来的每个块的大小,chunk overlap是指每个块之间重复的大小 CharacterTextSplitter(separator="",chunk_size=5,chunk_overlap=0) 一句话进行分割 text_splitter.split_text('a b c d e f') 多句话分割(传一个可迭代对象,列表) text_splitter.create_documents('a b c d e f','e f g h')
P02_project data project1 db.py from langchain_chroma import Chroma from langchain_community.document_loaders import TextLoader from langchain_text_splitters import CharacterTextSplitter from P04_RAG.P02_project.project1.model import embedding
from langchain_community.chat_models import ChatTongyi from langchain_community.embeddings import DashScopeEmbeddings from dotenv import load_dotenv ### 加载环境变量 load_dotenv()
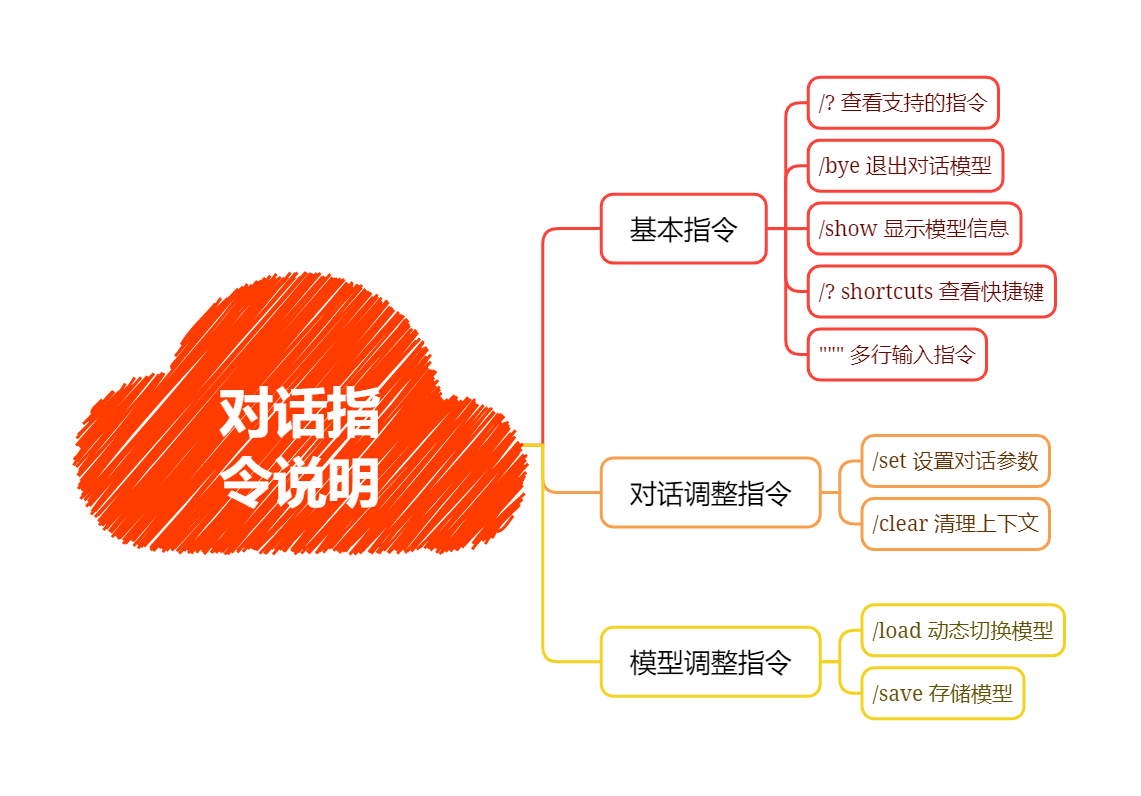
[root@bogon ~]# ollama run qwen2:0.5b >>> /? Available Commands: /set Set session variables /show Show model information /load <model> Load a session or model /save <model> Save your current session /clear Clear session context /bye Exit /?, /help Help for a command /? shortcuts Help for keyboard shortcuts
[root@bogon ~]# ollama run qwen2:0.5b >>> /show Available Commands: /show info 查看模型的基本信息 /show license 查看模型的许可信息 /show modelfile 查看模型的制作源文件Modelfile /show parameters 查看模型的内置参数信息 /show system 查看模型的内置Sytem信息 /show template 查看模型的提示词模版
/show info 查看模型的基本信息
1 2 3 4 5
>>> /show info Model details: Family qwen2 模型名称 Parameter Size 494.03M 模型大小 Quantization Level Q4_0 模型量化级别
/show license 查看模型的许可信息—开源软件的许可协议
1 2 3 4 5 6 7 8
>>> /show license
Apache License Version 2.0, January 2004 http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION ............................................................
/show modelfile 查看模型的制作源文件Modelfile
modelfile :文件是用来制作私有模型的脚步文件,后续课程学习
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
>>> /show modelfile # Modelfile generated by "ollama show" # To build a new Modelfile based on this, replace FROM with: # FROM qwen2:0.5b
FROM /root/ollama/blobs/sha256-8de95da68dc485c0889c205384c24642f83ca18d089559c977ffc6a3972a71a8 TEMPLATE "{{ if .System }}<|im_start|>system {{ .System }}<|im_end|> {{ end }}{{ if .Prompt }}<|im_start|>user {{ .Prompt }}<|im_end|> {{ end }}<|im_start|>assistant {{ .Response }}<|im_end|> " PARAMETER stop <|im_start|> PARAMETER stop <|im_end|> LICENSE """ ......................................................................
/show parameters 查看模型的内置参数信息
1 2 3 4
>>> /show parameters Model defined parameters: stop "<|im_start|>" stop "<|im_end|>"
/show system 查看模型的内置system信息—system常常用来定一些对话角色扮演
1 2
>>> /show system No system message was specified for this model.
/show template 查看模型的提示词模版
template:是最终传入大模型的字符串模版,模版中的内容由上层应用动态传入
1 2 3 4 5 6 7
>>> /show template {{ if .System }}<|im_start|>system {{ .System }}<|im_end|> {{ end }}{{ if .Prompt }}<|im_start|>user {{ .Prompt }}<|im_end|> {{ end }}<|im_start|>assistant {{ .Response }}<|im_end|>
/? shortcuts 指令
查看在控制台中可用的快捷键
1 2 3 4 5 6 7 8 9 10 11 12 13
>>> /? shortcuts Available keyboard shortcuts: Ctrl + a 移动到行头 Ctrl + e 移动到行尾 Ctrl + b 移动到单词左边 Ctrl + f 移动到单词右边 Ctrl + k 删除游标后面的内容 Ctrl + u 删除游标前面的内容 Ctrl + w 删除游标前面的单词
Ctrl + l 清屏 Ctrl + c 停止推理输出 Ctrl + d 退出对话(只有在没有输入时才生效)
>>> /set parameter Available Parameters: /set parameter seed <int> Random number seed /set parameter num_predict <int> Max number of tokens to predict /set parameter top_k <int> Pick from top k num of tokens /set parameter top_p <float> Pick token based on sum of probabilities /set parameter num_ctx <int> Set the context size /set parameter temperature <float> Set creativity level /set parameter repeat_penalty <float> How strongly to penalize repetitions /set parameter repeat_last_n <int> Set how far back to look for repetitions /set parameter num_gpu <int> The number of layers to send to the GPU /set parameter stop <string> <string> ... Set the stop parameters
>>> /set format json Set format to 'json' mode. >>> 您好 {"response":"你好,欢迎光临,请问有什么我可以帮助您的吗?"} >>> /set noformat Disabled format. >>> 您好 Hello! How can I assist you?
输出对话统计日志
1 2 3 4 5 6 7 8 9 10 11 12 13
>>> /set verbose Set 'verbose' mode. >>> 您好 您好!我需要您的信息,以便回答您的问题。请问您能告诉我更多关于这个主题的信息吗?
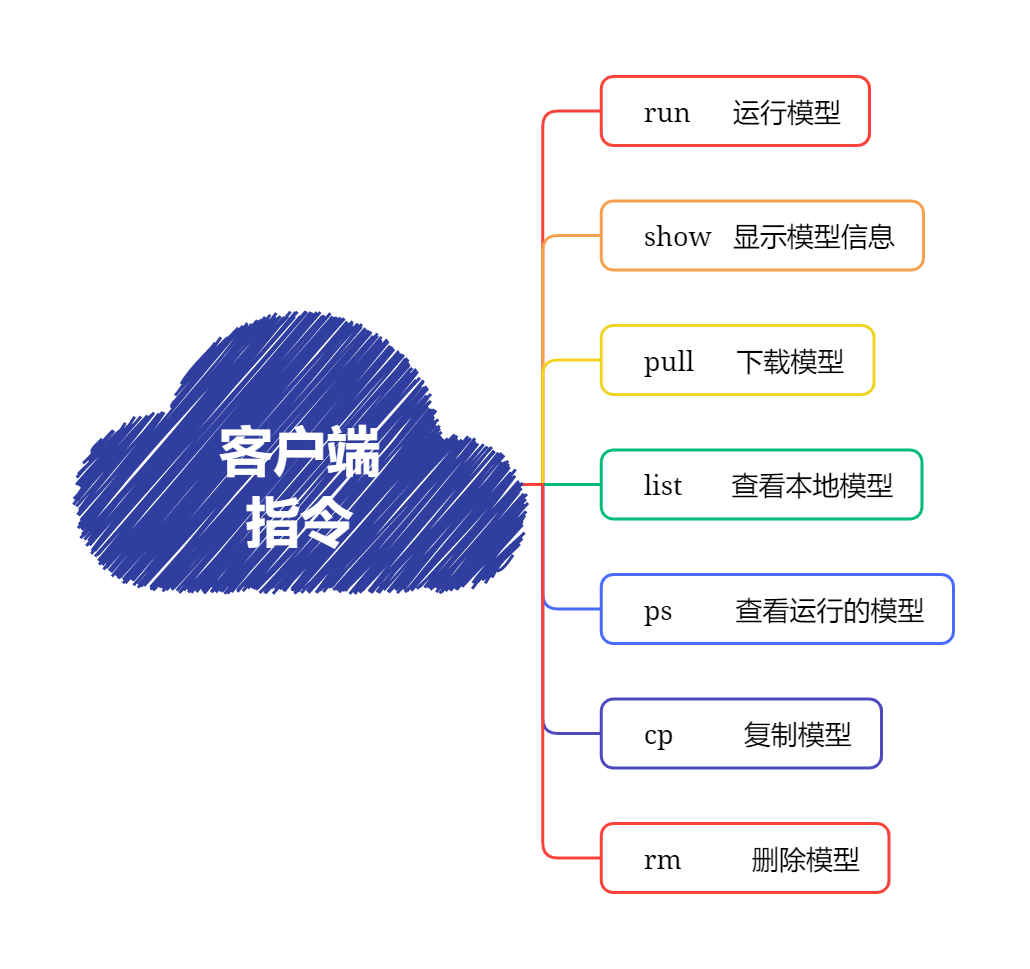
[root@bogon ~]# ollama list NAME ID SIZE MODIFIED qwen2:latest e0d4e1163c58 4.4 GB 10 minutes ago deepseek-coder:latest 3ddd2d3fc8d2 776 MB 3 hours ago qwen2:0.5b 6f48b936a09f 352 MB 8 hours ago [root@bogon ~]# ollama ls NAME ID SIZE MODIFIED qwen2:latest e0d4e1163c58 4.4 GB 10 minutes ago deepseek-coder:latest 3ddd2d3fc8d2 776 MB 3 hours ago qwen2:0.5b 6f48b936a09f 352 MB 8 hours ago
[root@bogon ~]# ollama ps NAME ID SIZE PROCESSOR UNTIL deepseek-coder:latest 3ddd2d3fc8d2 1.3 GB 100% CPU About a minute from now
列表字段说明:
NAME:大模型名称
ID:唯一ID
SIZE:模型大小
PROCESSOR:资源占用
UNTIL:运行存活时长
rm 命令
删除本地大模型,RM命令没其它参数
1 2 3 4 5 6 7 8 9 10 11 12
[root@localhost system]# ollama ls NAME ID SIZE MODIFIED qwen2:latest e0d4e1163c58 4.4 GB 16 hours ago deepseek-coder:latest 3ddd2d3fc8d2 776 MB 19 hours ago qwen2:0.5b 6f48b936a09f 352 MB 24 hours ago [root@localhost system]# ollama rm qwen2:0.5b deleted 'qwen2:0.5b' [root@localhost system]# ollama ls NAME ID SIZE MODIFIED qwen2:latest e0d4e1163c58 4.4 GB 16 hours ago deepseek-coder:latest 3ddd2d3fc8d2 776 MB 19 hours ago [root@localhost system]#
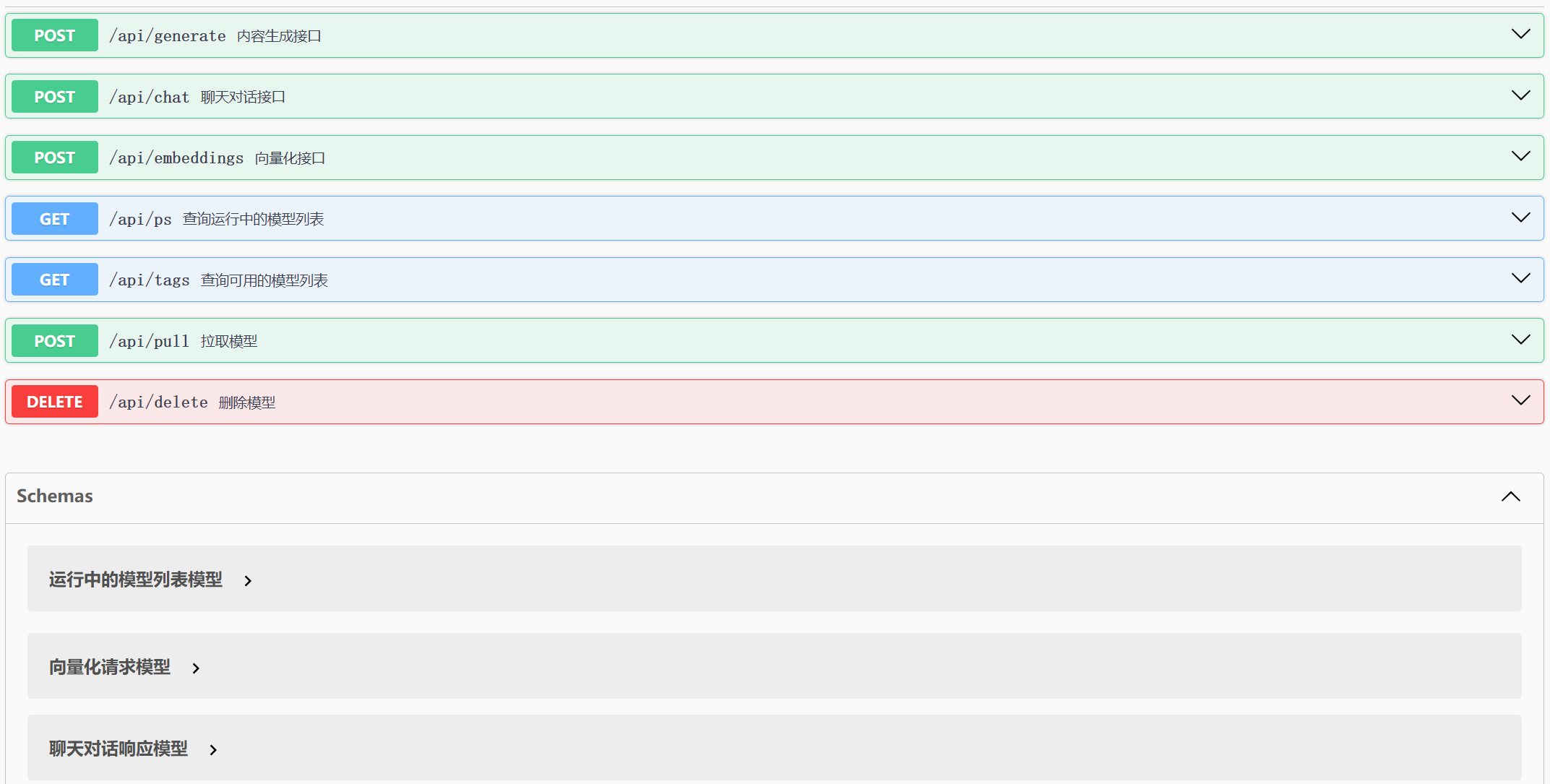
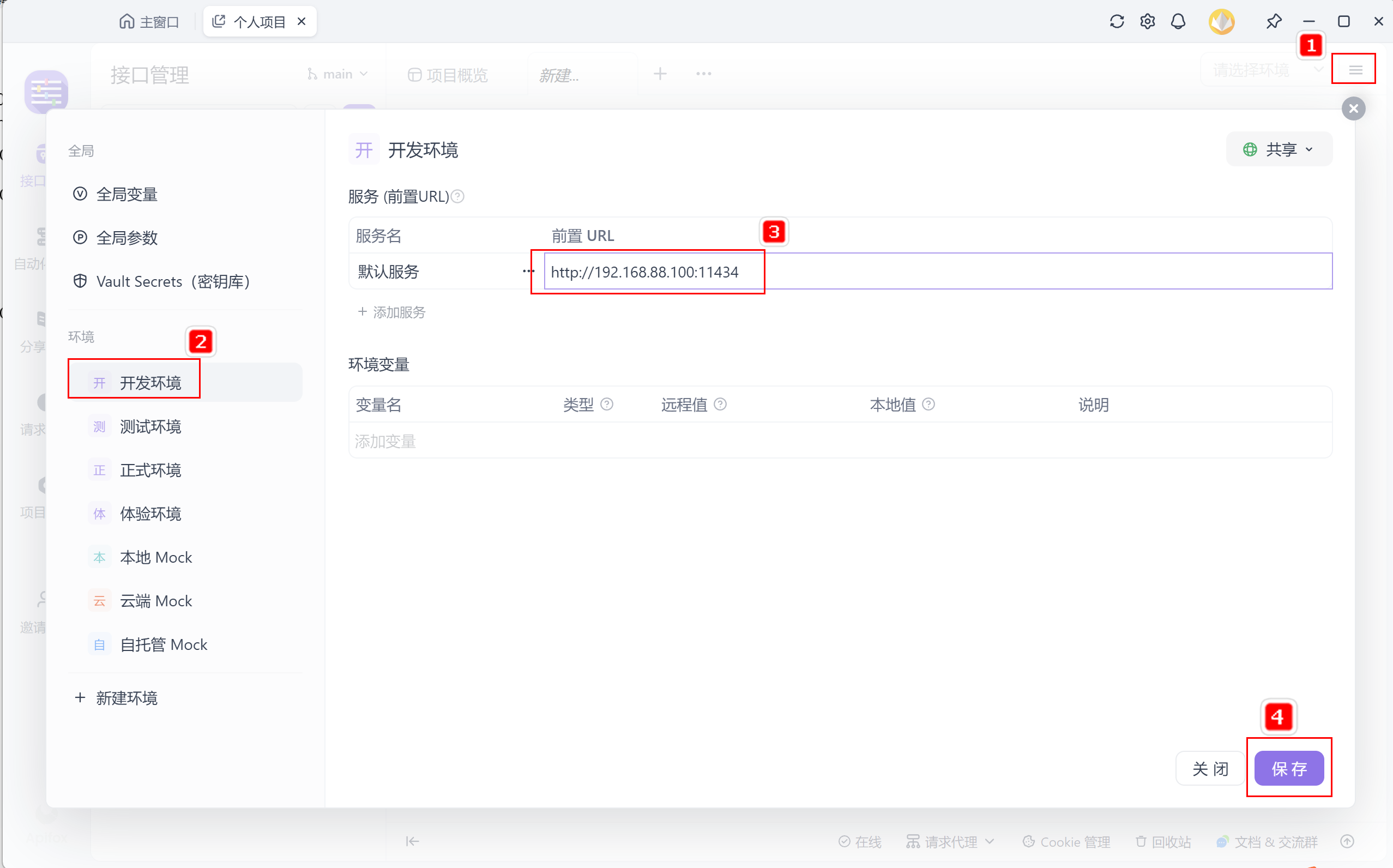
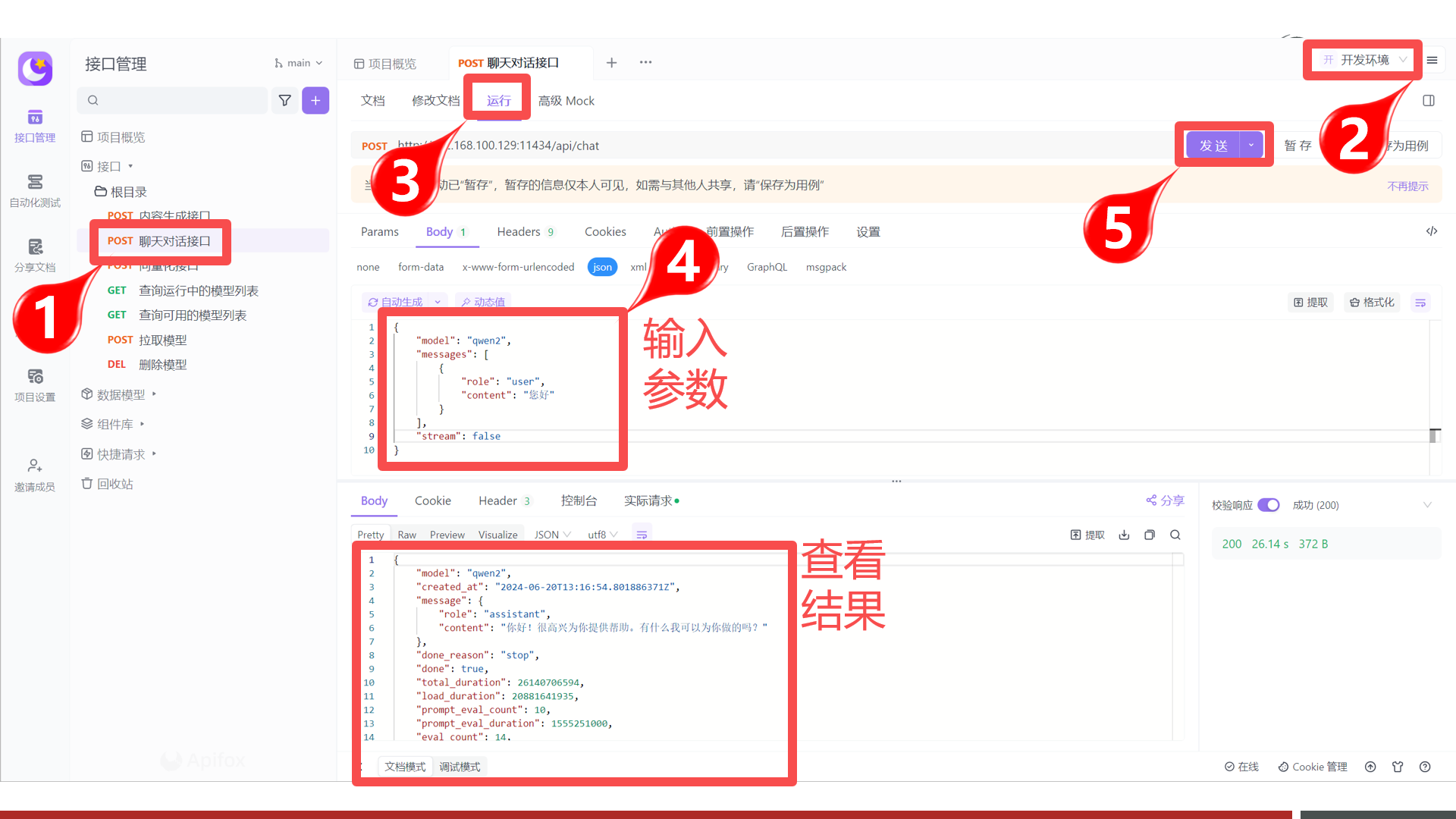
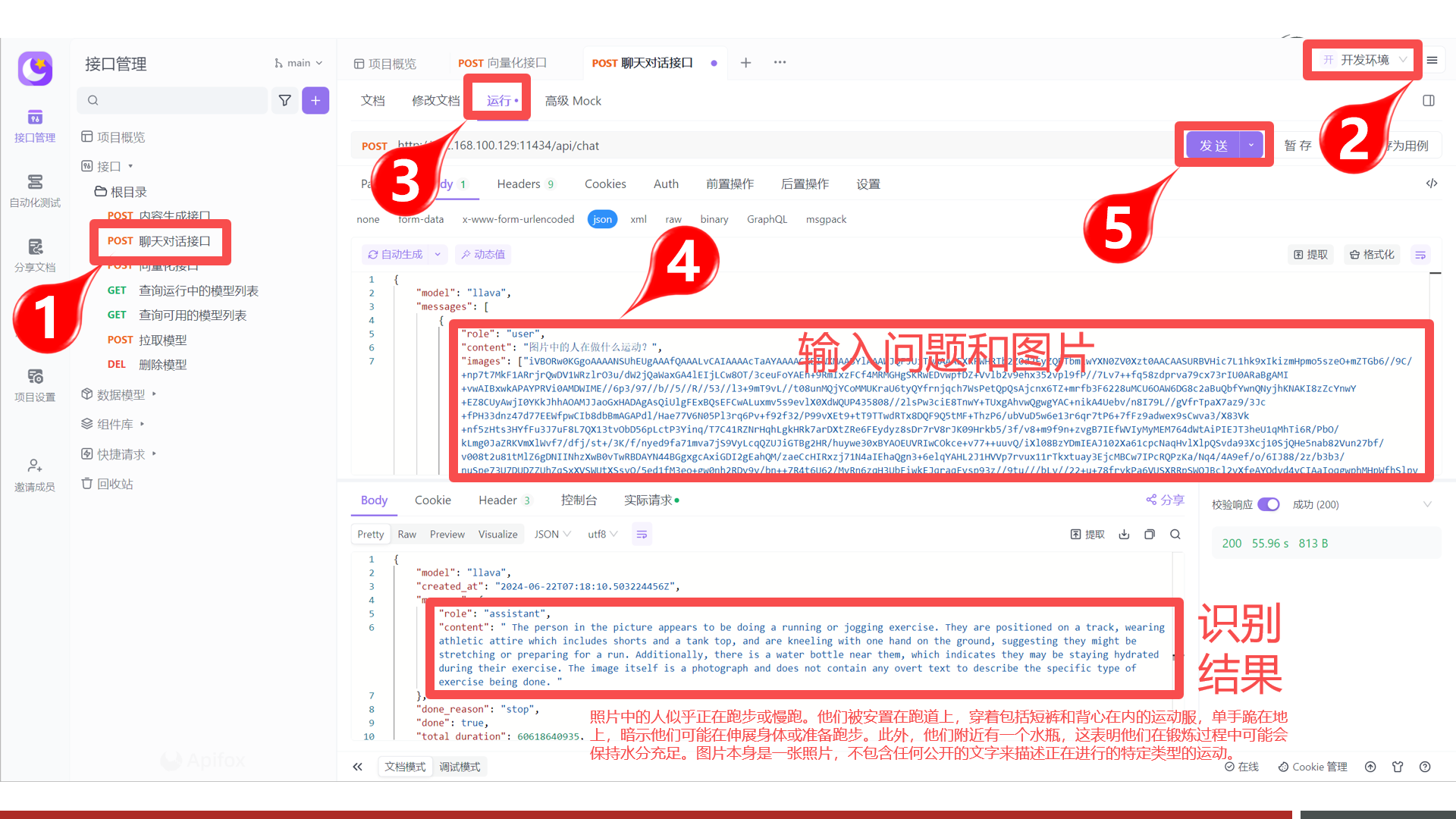
【掌握】OllamaAPI 详解
学习目标
掌握基于Ollama API接口,实现基于API的方式访问
HTTP基础知识
什么是HTTP
HTTP,全称为超文本传输协议(HyperText Transfer Protocol),是互联网上应用最为广泛的一种网络协议。它是客户端和服务器之间进行通信的规则集合,允许将超文本标记语言(HTML)文档从Web服务器传输到Web浏览器。简而言之,HTTP是Web浏览器和Web服务器之间的“语言”,使得用户能够浏览网页、下载文件、提交表单等。
{ "model":"qwen2.5:0.5b", "messages":[ { "role":"string", "content":"string", "images":"string" } ], "format":"string", "stream":true, "keep_alive":"string", "tools":[ { "type":"function", "function":{ "name":"get_current_weather", "description":"Get the current weather for a location", "parameters":{ "type":"object", "properties":{ "location":{ "type":"string", "description":"The location to get the weather for, e.g. San Francisco, CA" }, "format":{ "type":"string", "description":"The format to return the weather in, e.g. 'celsius' or 'fahrenheit'", "enum":["celsius","fahrenheit"] } }, "required":["location","format"] } } } ], "options":{ "seed":0, "top_k":0, "top_p":0, "repeat_last_n":0, "temperature":0, "repeat_penalty":0, "stop":[ "string" ] } }